Decoding Animal Behavior: A Comprehensive Guide to Hidden Markov Models in Tracking Data Analysis
Hidden Markov Models (HMMs) have emerged as a powerful statistical framework for classifying animal behavior from tracking data, enabling researchers to infer unobserved behavioral states from observable movement patterns.
Decoding Animal Behavior: A Comprehensive Guide to Hidden Markov Models in Tracking Data Analysis
Abstract
Hidden Markov Models (HMMs) have emerged as a powerful statistical framework for classifying animal behavior from tracking data, enabling researchers to infer unobserved behavioral states from observable movement patterns. This article provides a comprehensive overview for researchers and drug development professionals, covering foundational concepts, practical methodologies, and advanced applications. We explore how HMMs identify discrete behavioral modes such as foraging, resting, and navigating by analyzing movement metrics like step lengths and turning angles. The content addresses critical challenges including scale dependence and model selection, while validating HMM performance against alternative machine learning approaches. Through examples from diverse species and experimental settings, we demonstrate HMMs' transformative potential for preclinical research, particularly in quantifying behavioral outcomes in disease models and therapeutic interventions.
The Statistical Foundation of HMMs in Animal Behavior Analysis
Within the framework of a thesis on classifying animal behavior from tracking data, this document details the core concepts of Hidden Markov Models (HMMs) and provides a practical protocol for their application. HMMs are powerful statistical tools for analyzing sequential data where the underlying system states are not directly observable [1] [2].
Theoretical Foundation: Core Components of an HMM
An HMM is defined by a finite set of hidden states, a set of possible observations, and three probability distributions [1] [2]:
- Hidden States (
S): The true, unobservable conditions of the system. In behavioral ecology, these represent distinct behavioral modes (e.g., Resting, Exploring, Navigating) [3]. - Observation Sequence (
O): The data that is measured and recorded. In tracking studies, this typically consists of movement metrics derived from location data [4]. - Markov Property: The assumption that the next hidden state depends only on the current state, independent of all prior states [5].
- Initial State Probabilities (
π): The probability distribution over the initial behavioral state at the beginning of the sequence. - Transition Probabilities (
A): The matrix defining the probability of switching from one behavioral state to another [3]. - Emission Probabilities (
B): The probability of making a specific observation (e.g., a particular step length) given that the animal is in a specific behavioral state [1].
Table 1: The Core Parameters of a Hidden Markov Model
| Parameter | Notation | Description | Role in Animal Behavior Classification |
|---|---|---|---|
| Hidden States | S |
The true, unobservable behavioral modes. | Represents behaviors like Resting, Exploring, and Navigating [3]. |
| Observations | O |
The recorded, quantifiable data sequence. | Derived movement metrics such as step length and turning angle [4]. |
| Initial Probabilities | π |
The likelihood of starting in each state. | The assumed probability of an animal's initial activity upon tracking start. |
| Transition Probabilities | A |
The probability of moving from one state to another. | Models behavioral persistence and transitions (e.g., Exploring → Navigating) [3]. |
| Emission Probabilities | B |
The probability of an observation being generated from a state. | Links raw data (e.g., short step lengths) to a behavioral state (e.g., Resting) [4]. |
Quantitative Models for Behavioral States
The emission probabilities are defined by state-dependent distributions. For animal movement data, the following models are standard [4]:
- Step Lengths (
L) are typically modeled using a Gamma distribution, as they are continuous and non-negative. - Turning Angles (
ϕ) are modeled using a von Mises distribution, as they are circular (support on-πtoπ).
Table 2: Standard State-Dependent Distributions for Movement Metrics
| Observation Metric | Support | Standard Distribution | State-Dependent Parameters |
|---|---|---|---|
Step Length (L) |
L ≥ 0 |
Gamma | Shape ( kj ), Rate ( \thetaj ) (or Mean ( \muj ), SD ( \sigmaj )) |
Turning Angle (ϕ) |
-π < ϕ ≤ π |
Von Mises | Mean Direction ( \muj ), Concentration ( \kappaj ) |
Experimental Protocol: HMM-Based Behavioral Classification
This protocol outlines the key steps for applying an HMM to animal tracking data, based on established methodologies [3] [4].
Data Acquisition and Preprocessing
- Apparatus: Utilize a testing arena appropriate for the species and behavior of interest. For visual cliff tests, this involves a raised table with a checkerboard pattern and a transparent acrylic plate to create a depth illusion, surrounded by a circular enclosure to minimize corner bias [3].
- Data Collection: Record high-resolution video (e.g., 30 frames per second) from above the apparatus [3].
- Pose Estimation: Use deep learning-based software (e.g., DeepLabCut) to extract the animal's body center coordinates in each video frame [3].
- Movement Metric Calculation: From the
(x, y)coordinates, compute the step lengths and turning angles for each time interval.- Step Length (
l_t): The Euclidean distance between consecutive coordinates:l_t = √( (x_t - x_{t-1})² + (y_t - y_{t-1})² )[3]. - Turning Angle (
ϕ_t): The change in direction, calculated from three consecutive coordinates.
- Step Length (
Model Definition and Training
- Specify Number of States (
N): Choose a biologically plausible number of hidden behavioral states (e.g.,N=3: Resting, Exploring, Navigating) [3]. - Initialize Parameters: Make initial guesses for the probability matrices
π,A, and the parameters for the Gamma and von Mises distributions for each state. - Train with Baum-Welch Algorithm: Use the Expectation-Maximization (EM) algorithm to find the model parameters that maximize the likelihood of the observed sequence of step lengths and turning angles [6] [2]. This iterative algorithm refines the initial parameter estimates.
State Decoding and Validation
- Decode Behavioral Sequence: Apply the Viterbi algorithm to the trained model and the observed data to determine the single most likely sequence of hidden behavioral states across time [6] [2].
- Biological Validation: Correlate the decoded state sequence with the original video footage and known biological facts to validate that the classified states correspond to meaningful behaviors [3].
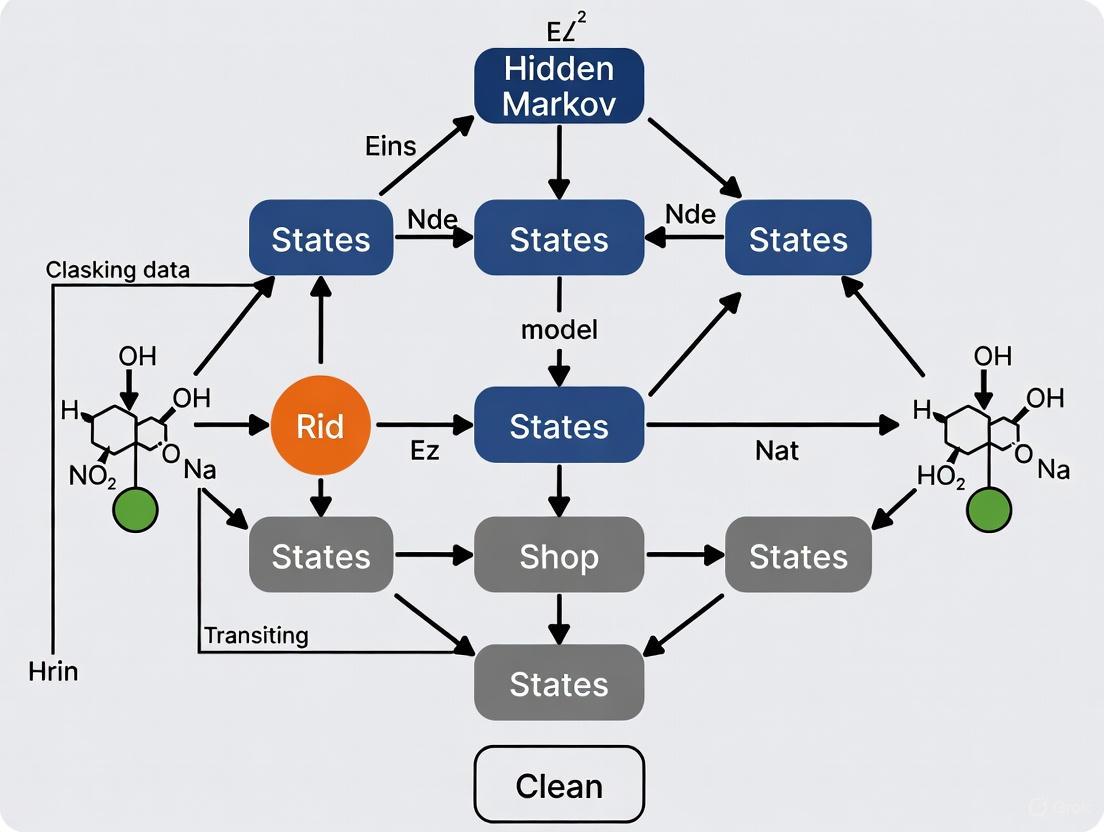
Visualizing the HMM Framework
The following diagram illustrates the logical structure and dependencies of a generic HMM, which underpins the behavioral classification workflow.
HMM Structure and Dependencies
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 3: Key Materials and Software for HMM-Based Behavioral Analysis
| Item Name | Function / Rationale |
|---|---|
| DeepLabCut | Open-source software for markerless pose estimation based on deep learning. Used to extract body center coordinates from video footage [3]. |
| Visual Cliff Apparatus | A controlled environment to test depth perception and visually guided behavior in rodents, consisting of a raised table with a high-contrast pattern and a transparent acrylic floor [3]. |
| Graphviz | Open-source graph visualization software. Its DOT language is used to create clear diagrams of graph structures, including HMM architectures [7]. |
| Pomegranate Library | A Python library that implements probabilistic models, including HMMs, with built-in functions for model training, inference, and visualization [8]. |
| Baum-Welch Algorithm | An Expectation-Maximization (EM) algorithm used to train HMMs by finding the unknown parameters that maximize the likelihood of the observed data [6] [2]. |
| Viterbi Algorithm | A dynamic programming algorithm used for decoding the most probable sequence of hidden states given a sequence of observations and a trained HMM [6] [2]. |
Advanced Consideration: Autoregressive HMMs for High-Resolution Data
Standard HMMs assume observations are conditionally independent given the state. For high-resolution tracking data (e.g., >10 Hz), this assumption is often violated due to movement momentum, leading to strong within-state serial correlation in step lengths and turning angles [4]. To address this, Autoregressive HMMs (AR-HMMs) can be employed. In an AR-HMM, the mean of the state-dependent distribution (e.g., for step length) depends not only on the current state but also on the previous p observations [4]:
μ_{t,j} = Σ_{k=1}^{p} φ_{j,k} * x_{t-k} + (1 - Σ_{k=1}^{p} φ_{j,k}) * μ_j
This formulation more accurately captures the dynamics of high-resolution movement, leading to improved inference and state decoding [4].
In the analysis of animal movement, Hidden Markov Models (HMMs) have emerged as a powerful statistical tool for identifying latent behavioral states from observed tracking data. The core mathematical framework of HMMs rests on two fundamental components: transition probabilities, which govern the dynamics between hidden behavioral states, and emission distributions, which describe how observable movement metrics are generated from these underlying states [1] [9]. This framework enables researchers to move beyond simple descriptive metrics and model the complex, dynamic processes that characterize animal behavior, revealing patterns that traditional analytical methods often overlook [10].
In movement ecology, HMMs typically model sequences of movement steps derived from telemetry data. The hidden states represent behavioral modes (e.g., resting, foraging, traveling), while observations usually consist of step lengths (distance between consecutive locations) and turning angles (directional changes) [9]. The conditional independence structure of HMMs—where observations depend only on the current state, and states depend only on the previous state—provides a computationally tractable framework for decoding the behavioral processes underlying movement trajectories [1] [11].
Core Mathematical Framework
The Hidden Markov Model Structure
A Hidden Markov Model is a probabilistic time series model comprising an unobserved state sequence $(S1, S2, ..., ST)$ and an observed sequence $(Y1, Y2, ..., YT)$ [1]. In animal movement applications, the hidden states $St$ typically represent behavioral modes, while observations $Yt$ are movement metrics derived from tracking data [9]. The model is defined by three core elements:
- The initial state distribution $\bm{\delta} = (\delta1, \delta2, ..., \deltaN)$ where $\deltai = \Pr(S_1 = i)$ specifies the probability of starting in state $i$ [9] [11].
- The state transition probability matrix $\bm{\Gamma} = (\gamma{ij})$, where $\gamma{ij} = \Pr(St = j | S{t-1} = i)$ defines the probability of transitioning from state $i$ to state $j$ between times $t-1$ and $t$ [1] [9].
- The emission distributions $f(Yt | St = j, \bm{\theta}^{(j)})$, which describe the probability of observing $Y_t$ given the active state $j$ with state-dependent parameters $\bm{\theta}^{(j)}$ [1] [9].
The following diagram illustrates the conditional dependency structure of a standard HMM, showing how the hidden state sequence evolves according to Markov dynamics and generates observations at each time point.
Transition Probabilities
The transition probability matrix $\bm{\Gamma}$ is an $N \times N$ matrix where each entry $\gamma{ij}$ satisfies $0 \leq \gamma{ij} \leq 1$ and each row sums to unity: $\sum{j=1}^N \gamma{ij} = 1$ for all $i$ [9]. This matrix captures the temporal persistence and switching dynamics between behavioral states. For example, high diagonal values ($\gamma_{ii}$) indicate persistent states where animals tend to maintain their current behavior, while higher off-diagonal values indicate more frequent behavioral switching [9] [10].
In animal movement applications, transition probabilities are often modeled as functions of environmental covariates to understand how external factors influence behavioral dynamics [9]. This is typically achieved using a multinomial logit link function:
$$\gamma{ij}^{(t)} = \frac{\exp(\eta{ij}^{(t)})}{\sum{k=1}^N \exp(\eta{ik}^{(t)})}$$
where $\eta{ij}^{(t)} = \beta0^{(ij)} + \beta1^{(ij)} x{1t} + \cdots + \betap^{(ij)} x{pt}$ for $i \neq j$, and $\eta_{ii}^{(t)} = 0$ to ensure identifiability [9]. This formulation allows researchers to test specific hypotheses about how environmental conditions, such as habitat type or time of day, affect the probability of switching between different behavioral states.
Emission Distributions
Emission distributions define the relationship between the hidden behavioral states and the observed movement metrics. In animal movement applications, the bivariate observation $Yt = (lt, \phit)$ typically consists of step length $lt$ (non-negative continuous) and turning angle $\phi_t$ (circular, ranging from $-\pi$ to $\pi$) [9]. The standard approach assumes conditional independence between these metrics given the state:
$$f(Yt | St = j) = f(lt | St = j) \cdot f(\phit | St = j)$$
The most common distributional choices reflect the distinct nature of each movement metric:
Step Lengths are typically modeled using a gamma distribution [4] [9]:
$lt | St = j \sim \text{Gamma}(\muj, \sigmaj)$
parameterized by a state-dependent mean $\muj$ and standard deviation $\sigmaj$, where both parameters are strictly positive. The gamma distribution accommodates the right-skewed nature of movement step lengths while maintaining computational tractability.
Turning Angles are commonly modeled using a von Mises distribution [9]:
$\phit | St = j \sim \text{von Mises}(\lambdaj, \kappaj)$
where $\lambdaj$ is the state-specific mean angle (representing directional bias) and $\kappaj$ is the concentration parameter (representing directional persistence, with higher values indicating more concentrated angles around the mean).
Table 1: Standard Emission Distributions for Animal Movement HMMs
| Observation | Distribution | Parameters | Biological Interpretation |
|---|---|---|---|
| Step Length | Gamma | $\muj$: mean$\sigmaj$: standard deviation | Speed/displacement; higher $\mu_j$ indicates faster movement |
| Turning Angle | von Mises | $\lambdaj$: mean angle$\kappaj$: concentration | Directional persistence; higher $\kappa_j$ indicates more directed movement |
For high-resolution data where the conditional independence assumption may be violated due to momentum in movement, autoregressive HMMs extend this framework by incorporating lagged observations into the emission distributions [4]. For example, the state-dependent mean for step lengths can be modeled as:
$$\mu{t,j}^{\text{step}} = \sum{k=1}^{pj^{\text{step}}}\phi{j,k}^{\text{step}} l{t-k} + \Bigl(1-\sum{k=1}^{pj^{\text{step}}}\phi{j,k}^{\text{step}}\Bigr) \mu_j^\text{step}$$
where $\phi{j,k}^{\text{step}}$ are state-specific autoregressive coefficients, and $pj^{\text{step}}$ is the autoregressive order for state $j$ [4]. Similar structures can be applied to turning angles, effectively capturing the within-state serial correlation induced by movement momentum in high-frequency data.
Advanced Modeling Considerations
Scale Dependence in HMM Parameters
A critical consideration when applying HMMs to animal movement data is scale dependence—both transition probabilities and emission parameters depend strongly on the temporal resolution of the data [9]. This occurs because HMMs are discrete-time models whose parameters are tied to the specific time interval at which observations are recorded.
Transition probabilities reflect behavioral switching rates over the specific sampling interval. As the time between observations changes, so does the interpretation of these probabilities. For example, a transition probability of $\gamma_{12} = 0.1$ has different behavioral implications for data collected at 1-second versus 1-hour intervals [9].
Similarly, emission parameters are scale-dependent. Gamma distribution parameters for step lengths describe movement characteristics specific to the sampling rate. A "resting" state identified from high-frequency data might appear as a "slow exploration" state in lower-frequency data [9].
This scale dependence has important implications:
- It generally precludes comparing or combining tracking data collected at irregular time intervals
- It complicates comparisons between studies using different sampling rates
- Parameters and state classifications are interpretable only with reference to the specific temporal resolution of the data
Table 2: Effects of Temporal Scaling on HMM Components
| Model Component | Scale Dependence | Practical Implication |
|---|---|---|
| Transition probabilities | $\gamma_{ij}$ depends on time step | Switching rates cannot be compared across studies with different sampling intervals |
| Step length parameters | $\muj$, $\sigmaj$ depend on time step | Absolute speed/displacement values are sampling-rate specific |
| State classification | Overall behavioral classification | Same behavior may be classified into different states at different temporal resolutions |
| Model selection | Optimal number of states $N$ | Different numbers of states may be identified at different sampling rates |
Covariate-Dependent Transition Probabilities
To understand the drivers of behavioral switching, HMMs can incorporate time-varying covariates into the transition probability matrix [9]. As shown in Section 2.2, this is typically achieved using a multinomial logistic regression framework where:
$$\gamma{ij}^{(t)} = \frac{\exp(\eta{ij}^{(t)})}{\sum{k=1}^N \exp(\eta{ik}^{(t)})}$$
with $\eta{ij}^{(t)} = \beta0^{(ij)} + \beta1^{(ij)} x{1t} + \cdots + \betap^{(ij)} x{pt}$ for $i \neq j$ [9]. This approach enables researchers to test specific hypotheses about how internal (e.g., hunger state) or external (e.g., habitat characteristics, environmental conditions) factors influence the probability of switching between behavioral states.
Experimental Protocol: Implementing HMMs for Animal Behavior Classification
Workflow for HMM Application
The following diagram outlines the complete workflow for applying HMMs to classify animal behavior from tracking data, from data collection through biological inference.
Step-by-Step Methodology
Step 1: Data Collection and Preprocessing
- Collect animal location data at consistent time intervals using GPS, radio telemetry, or video tracking [10]
- Clean data to remove obvious errors and interpolation artifacts
- For high-resolution data (e.g., >1 Hz), consider appropriate filtering or smoothing techniques
Step 2: Movement Metric Calculation
- Calculate step lengths as Euclidean distances between consecutive locations: $lt = \|\bm{x}{t+1} - \bm{x}_t\|$
- Calculate turning angles as directional changes between consecutive movement steps: $\phit = \text{atan2}(y{t+1} - yt, x{t+1} - xt) - \text{atan2}(yt - y{t-1}, xt - x{t-1})$ with appropriate wrapping to ensure $\phit \in (-\pi, \pi]$ [9]
Step 3: Model Specification
- Determine the number of states $N$ based on biological knowledge and model selection criteria (AIC/BIC) [9] [12]
- Select appropriate emission distributions (typically gamma for step lengths, von Mises for turning angles) [9]
- For high-resolution data with strong serial correlation, consider autoregressive HMM extensions [4]
Step 4: Parameter Estimation
- Implement the Baum-Welch algorithm (a special case of Expectation-Maximization) to estimate model parameters [11] [13]
- The algorithm iterates between:
- E-step: Compute expected state probabilities using forward-backward algorithm
- M-step: Update parameters to maximize expected log-likelihood
- Multiple random initializations are recommended to avoid local maxima
Step 5: State Decoding
- Apply the Viterbi algorithm to find the most likely sequence of hidden states given the estimated parameters and observations [11] [13]
- This dynamic programming approach efficiently computes $\arg\max{S{1:T}} \Pr(S{1:T} | Y{1:T}, \bm{\theta})$
Step 6: Biological Interpretation and Validation
- Interpret decoded states ecologically based on their movement characteristics and temporal patterns [10]
- Validate model fit using pseudo-residuals and goodness-of-fit tests
- Compare state classifications with independent behavioral observations when available
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Computational Tools for HMM Analysis in Animal Movement
| Tool/Category | Specific Examples | Function/Purpose |
|---|---|---|
| HMM Software Libraries | hmms (Python) [14], PyHHMM [12] |
Implement core HMM algorithms (forward-backward, Viterbi, Baum-Welch) |
| Movement Data Processing | moveHMM (R), amt (R) |
Calculate movement metrics, prepare data for HMM analysis |
| Animal Tracking Systems | GPS collars, radio telemetry, video tracking with DeepLabCut [10] | Collect high-resolution location data for movement analysis |
| Model Selection Criteria | AIC, BIC [12] | Compare models with different numbers of states or structures |
| Visualization Tools | ggplot2 (R), matplotlib (Python) |
Create diagnostic plots and visualize state-dependent distributions |
The mathematical framework of transition probabilities and emission distributions provides a powerful foundation for classifying animal behavior from movement data. The HMM approach captures the inherent dynamics of behavioral processes while accounting for the uncertainty in assigning discrete states to continuous movement patterns. While the standard HMM formulation has proven valuable across numerous applications, recent extensions addressing scale dependence [9] and autocorrelation in high-resolution data [4] continue to enhance the methodology's robustness and biological realism. When implemented with careful attention to temporal scale, appropriate distributional assumptions, and thorough validation, HMMs offer researchers a principled framework for decoding the behavioral mechanisms underlying animal movement trajectories.
The analysis of animal movement is a cornerstone of behavioral ecology, critical for understanding species distribution, habitat use, and energy expenditure. Continuous movement paths, recorded via modern telemetry, present a analytical challenge: how to extract biologically meaningful patterns from a constant stream of location data. The framework of discrete behavioral states provides a powerful solution, positing that continuous movement arises from an underlying sequence of finite, functionally distinct behaviors such as foraging, migrating, and resting. Hidden Markov Models (HMMs) offer a robust statistical methodology for identifying these latent states from observed location data, enabling researchers to make ecological inferences about how animals interact with their environment [15] [16].
This application note outlines the biological and mathematical rationale for using discrete states, provides a comparative analysis of movement metrics, and details experimental protocols for implementing HMMs in behavioral classification.
Theoretical Foundation: Linking Discrete States to Continuous Paths
The Biological Basis for Behavioral States
Animal behavior is not a continuously variable process but is often organized into discrete, functional modes that serve specific purposes such as resource acquisition, predator avoidance, or reproduction. For example, a grey seal may switch between a directed transiting state to cover distance efficiently and a tortuous foraging state to locate and capture prey [15]. These states are driven by internal motivations and external environmental cues, creating a hierarchical structure where continuous movement execution is governed by discrete cognitive or motivational states.
The Mathematical Bridge: Hidden Markov Models
HMMs statistically formalize this biological concept. They treat the observed movement data (e.g., step lengths, turning angles) as emissions generated by an unobserved (hidden) Markov process that switches between a finite number of discrete behavioral states. The model assumes:
- The behavioral state at any time depends only on the state at the previous time step (the Markov property).
- Each state is characterized by a unique probability distribution for the movement metrics (e.g., a "transiting" state has a distribution of step lengths skewed toward larger values).
This framework successfully explains continuous movement paths because the model's output is a probabilistic sequence of these discrete states, creating a segmentation of the track into biologically interpretable segments [15] [10].
Quantitative Movement Metrics for State Classification
The choice of movement metrics is critical for effectively distinguishing between behavioral states. The following metrics, derived from raw location data, serve as the observed emissions for the HMM.
Table 1: Key Movement Metrics for Behavioral State Classification
| Metric | Calculation | Biological Interpretation | State Discrimination Value |
|---|---|---|---|
| Step Length | ( lt = \sqrt{(xt - x{t-1})^2 + (yt - y_{t-1})^2} ) [3] | Distance covered between consecutive locations. | High: Long steps suggest transiting; short steps suggest resting or foraging [16]. |
| Turning Angle | ( \thetat = \arctan^* (yt - y{t-1}, xt - x_{t-1}) ) | Change in direction of movement. | High: Angles near 0 indicate directed movement; angles near ±π indicate tortuous movement [15]. |
| Movement Persistence | ( dt = \gamma{b{t-1}} T(\theta{b{t-1}}) d{t-1} + N_2(0, \Sigma) ) [15] | Autocorrelation in speed and direction. | High: High γ (>0.5) indicates persistent, directed movement; low γ (<0.5) indicates less predictable movement [15]. |
Experimental Protocols for HMM Implementation
Protocol 1: Data Acquisition and Preprocessing for Aquatic Species
- Application: Classifying behavior from animal tracks with negligible measurement error (e.g., from acoustic telemetry or high-resolution GPS) [15].
- Materials: Animal tracking data (regular time intervals), computing environment (e.g., R programming language).
- Workflow:
- Data Filtering: Remove or correct obvious location outliers and fix any gaps in the time series.
- Metric Calculation: From the cleaned location data (x, y coordinates), calculate step lengths and turning angles for the entire track.
- HMM Fitting: Implement a HMM where the process equation for the movement is based on a correlated random walk. The model is defined by:
- Process Equation: ( dt = \gamma{b{t-1}} T(\theta{b{t-1}}) d{t-1} + N2(0, \Sigma) ), where ( dt ) is the movement vector, ( \gamma ) is the persistence parameter, ( T ) is a rotational matrix for the turning angle ( \theta ), and ( b_t ) is the behavioral state at time ( t ) [15].
- State-Dependent Distributions: Assume step lengths and turning angles come from distributions (e.g., gamma for step length, von Mises for turning angle) whose parameters are dependent on the behavioral state.
- Parameter Estimation: Fit the model using maximum likelihood methods, ideally with efficient computation packages like Template Model Builder (TMB) in R [15].
- State Decoding: Use the Viterbi algorithm to determine the most probable sequence of behavioral states from the observed data.
Protocol 2: Behavioral State Analysis in a Controlled Arena
- Application: Quantifying depth perception and its behavioral consequences in mice using a visual cliff test [3] [10].
- Materials: Visual cliff apparatus (circular arena recommended to reduce corner bias), overhead camera, DeepLabCut software for pose estimation [10].
- Workflow:
- Apparatus Setup: Construct a visual cliff using a table with a checkerboard pattern and a transparent acrylic plate extending beyond the edge to create a "deep" side. Use a circular enclosure to promote exploration [10].
- Experimental Trial: Place a mouse (e.g., wild-type C57BL/6J or retinal degeneration model) on a central platform facing the shallow side. Allow free exploration for a set period (e.g., 10 minutes) while recording from above [3].
- Motion Capture: Use DeepLabCut to track the body center coordinates (x, y) of the mouse throughout the trial at a defined sampling rate (e.g., 10 Hz) [3] [10].
- Metric Extraction: Calculate step length and turning angle from the coordinate data [3].
- HMM Analysis: Fit an HMM to the derived movement metrics to classify the mouse's behavior into discrete states such as Resting, Exploring, and Navigating [10]. The transition probabilities between these states reveal how the animal's behavioral mode is influenced by the visual cliff.
Critical Parameters and Method Selection
The temporal scale of data collection and the choice of analytical model are critical for making correct ecological inferences.
Table 2: Influence of Temporal Scale and Model Selection on Behavioral Inference
| Factor | Considerations | Impact on Inference |
|---|---|---|
| Temporal Scale (Time Step) | Fine-scale (e.g., 1 hour) vs. coarse-scale (e.g., 8 hours) data [16]. | Fine-scale: Can identify brief resting bouts during migration [16]. Coarse-scale: Smoothes behavioral transitions, better for distinguishing large-scale patterns like migration vs. residence [16]. |
| Model Selection | Hidden Markov Model (HMM) vs. Move Persistence Model (MPM) vs. Mixed-Membership Method (M4) [16]. | HMM: Excellent for identifying clear, discrete states from regular, low-error data [16]. MPM: Treats behavior as a continuum; can reveal fine-scale patterns missed by HMMs at short time steps [16]. M4: Makes fewer parametric assumptions, handles missing data, but requires careful interpretation [16]. |
| Number of States | Determined by model selection criteria (e.g., AIC) and biological knowledge [16]. | Over-specification leads to states with no biological meaning; under-specification collapses distinct behaviors into a single state [16]. |
Visualization of the HMM Framework and Workflow
Conceptual Framework of a Hidden Markov Model for Movement
Experimental and Analytical Workflow
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Resources for Behavioral Classification Studies
| Item | Function/Application | Examples/Specifications |
|---|---|---|
| Biotelemetry Transmitters | Attach to animal to collect location data. | Argos-linked Fastloc GPS tags (e.g., SPLASH10-F-385A) for marine species [16]; Acoustic transmitters for fine-scale positioning [15]. |
| Pose Estimation Software | Tracks animal position from video footage in controlled experiments. | DeepLabCut: An open-source tool for markerless pose estimation based on deep learning [3] [10]. |
| Computational Environment | Provides the platform for statistical modeling and analysis. | R programming environment: Use packages like moveHMM [15], swim [15], or M4 [16] for fitting HMMs and related methods. |
| Visual Cliff Apparatus | Standardized setup for testing visually guided behaviors in rodents. | Circular arena (e.g., 60 cm diameter) to minimize corner bias; transparent acrylic plate over a high-contrast checkerboard pattern [10]. |
In animal movement ecology, hidden Markov models (HMMs) have become a cornerstone technique for inferring unobserved behavioral states from tracking data [17]. These models operate on the principle that an animal's movement path is a manifestation of underlying, discrete behavioral modes, such as foraging, traveling, or resting. The process is twofold: a latent state process models the sequence of behaviors as a Markov chain, while an observation process links each behavioral state to a characteristic distribution of movement metrics [4]. The most commonly used metrics are step lengths (the distance between consecutive locations), turning angles (the change in direction), and speed [15] [18]. By analyzing the patterns in these metrics, HMMs can objectively segment a continuous movement track into meaningful behavioral sequences, providing profound insights into animal activity budgets, habitat selection, and energetics [17] [19].
Core Movement Metrics and Their Behavioral Significance
The power of HMMs lies in translating raw location data into behavioral inference by modeling the state-dependent distributions of key movement metrics. The table below summarizes how these metrics are interpreted for common behavioral states.
Table 1: Behavioral interpretation of core movement metrics in Hidden Markov Models.
| Behavioral State | Step Length / Speed | Turning Angle | Behavioral Interpretation |
|---|---|---|---|
| Encamped / Resting | Short steps; low speed [17] [20] | Uncorrelated or wide distribution [18] | Little displacement; activities like sleeping, grooming, or localized foraging [20] |
| Exploratory / Foraging | Highly variable; often intermediate [17] | High tortuosity; frequent large turns [18] | Area-restricted search (ARS); intensive search for resources like food or shelter [18] |
| Transit / Traveling | Long steps; high speed [17] [20] | Directed movement; low tortuosity (angles near 0) [15] [18] | Directed, persistent movement between distinct locations such as foraging grounds [20] |
Statistical Distributions in HMMs
In a standard HMM, these behavioral patterns are formally captured by specifying parametric distributions for the observations conditional on the state:
- Step Lengths are typically modeled using a gamma distribution due to their positive, continuous nature [4]. The Weibull distribution is also sometimes used [15].
- Turning Angles are circular quantities and are commonly modeled with a von Mises distribution, which is the circular analogue of the normal distribution [21] [4].
- Speed, which is closely related to step length, can be derived directly from the data and is often implicitly modeled through the step length distribution [22].
The model is defined by its initial state distribution δ and a transition probability matrix Γ, which governs the likelihood of switching from one state to another [4]. The forward algorithm is then used to compute the likelihood of the observed data, and the Viterbi algorithm is applied to decode the most probable sequence of hidden behavioral states [17].
Experimental Protocols for HMM Application
Data Pre-processing and Preparation
Objective: To transform raw telemetry data into a format suitable for HMM analysis.
- Data Sourcing: Collect animal location data from GPS tags or other telemetry systems. The data should ideally be collected at a regular time interval appropriate for the species and behaviors of interest [17].
- Data Cleaning: Address any data gaps or obvious errors (e.g., extreme outliers caused by GPS fix inaccuracy) [18].
- Metric Calculation:
- Step Lengths: Calculate the Euclidean distance between consecutive locations
(x_t, y_t)and(x_{t+1}, y_{t+1})[4]. - Turning Angles: Compute the relative turning angle
θ_tbetween three consecutive locations(x_{t-1}, y_{t-1}),(x_t, y_t), and(x_{t+1}, y_{t+1}). The angle is measured in radians(-π, π], where 0 indicates directed forward movement [21] [4]. - Speed: Derive speed by dividing the step length by the time interval between locations [22].
- Step Lengths: Calculate the Euclidean distance between consecutive locations
Model Fitting and Implementation
Objective: To fit an HMM to the prepared data and infer the underlying behavioral states.
- Model Formulation: Decide on the number of behavioral states
N(e.g., 2 or 3). This can be based on ecological knowledge, model selection criteria (e.g., AIC), or a desire to test specific hypotheses [21] [18]. - Parameter Estimation: Use numerical maximum likelihood estimation, often implemented in specialized R packages like
momentuHMMormoveHMM, to estimate the parameters of the state-dependent distributions (e.g., the mean and standard deviation for the gamma distribution of step lengths) and the state transition probability matrix [17] [23]. - State Decoding: Apply the Viterbi algorithm to the fitted model to determine the most likely sequence of behavioral states for the entire track [17].
- Model Validation (Critical Step): Where possible, validate the HMM-derived behaviors against direct observations or data from auxiliary sensors. For example:
- Use wet-dry sensors to validate "on-water/resting" states in seabirds [18].
- Use accelerometers to identify characteristic flapping or soaring movements in birds [19].
- Use time-depth recorders (TDR) to confirm diving and foraging events in marine animals [18].
- Even a small subset of validated data can be used in a semi-supervised framework to significantly improve model accuracy [18].
Advanced Methodological Considerations
Integrated and Enhanced HMM Frameworks
To address the complexities of animal movement, several advanced HMM frameworks have been developed:
HMM with Step Selection Functions (HMM-SSF): This integrated model combines the strengths of HMMs and step selection functions (SSFs). It classifies behaviors based on both movement characteristics and habitat selection, providing a more holistic view of space use and reducing bias in parameter estimates [17] [20]. For example, an analysis of plains zebra identified an "exploratory" state with not only fast, directed movement but also a stronger selection for grassland habitats [20].
Autoregressive HMMs (AR-HMMs): Standard HMMs assume that observations are conditionally independent given the state. This assumption is often violated in high-resolution data where momentum induces serial correlation within a behavioral state. AR-HMMs incorporate autoregressive components for both step lengths and turning angles, allowing the current value to depend on previous observations, which leads to more accurate inference [4].
Absolute Angle HMMs: Most HMMs use turning angles (relative direction). However, in some contexts, such as analyzing organelle movement within cells or movement with a global bias (e.g., towards a food source), using absolute angles (direction relative to a fixed axis) in a biased random walk (BRW) model can provide better fit and reveal biologically significant directional changes [21].
The Scientist's Toolkit: Essential Research Reagents
Table 2: Key tools, software packages, and sensors used in movement ecology for HMM-based analysis.
| Tool / Reagent | Type | Primary Function |
|---|---|---|
| GPS Loggers | Hardware | Collects high-resolution location data at pre-defined intervals [18]. |
| Accelerometers | Hardware | Measures fine-scale body movements and posture; used for behavior validation and model improvement [19] [18]. |
| Magnetometers | Hardware | Measures heading and angular velocity; useful for identifying low-acceleration behaviors like soaring [19]. |
| Wet-Dry Sensors | Hardware | Determines if an animal is in water or on land; validates resting/foraging states in marine species [18]. |
| Time Depth Recorders (TDR) | Hardware | Records dive profiles; validates underwater foraging behavior [18]. |
R package momentuHMM |
Software | Fits complex HMMs to animal tracking data, allowing for multiple data streams and covariates [17] [23]. |
R package moveHMM |
Software | Provides tools for pre-processing tracking data and fitting basic HMMs with step lengths and turning angles [21]. |
| Animal Tag Tools (Wiki) | Software/Resource | A collection of MATLAB functions for calibrating and processing data from various biologging sensors [19]. |
Workflow Visualization
The following diagram illustrates the standard workflow for classifying animal behavior using an HMM, from data collection to biological insight.
Figure 1: A standard workflow for behavioral classification using Hidden Markov Models, showing the key stages from raw data to biological insight.
Application Notes
Hidden Markov Models (HMMs) are powerful statistical tools for analyzing sequential data, defined by their memorylessness—the probability of transitioning to a new state depends only on the current state [24]. In animal research, HMMs infer hidden behavioral states (e.g., resting, foraging) from observable sensor data (e.g., movement patterns, accelerometer readings) [18] [19]. Their application has evolved from broad-scale ecological tracking to fine-scale biomedical investigation, enabling researchers to decode complex animal behaviors and physiological states with high precision.
Table 1: Evolution of HMM Applications in Animal Research
| Field of Application | Key Objective | Hidden States Inferred | Observable Data Used | Representative Study Models |
|---|---|---|---|---|
| Movement Ecology | Classify major behavioral modes and understand habitat use [18] [19]. | Resting, foraging, travelling, soaring flight, flapping flight [18] [19]. | GPS-derived step length and turning angle [18]; Accelerometer and magnetometer data [19]. | Albatrosses, Red-billed Tropicbirds [18] [19]. |
| Biomedical Research | Assess functional recovery and neural integration in disease models [3]. | Resting, Exploring, Navigating [3]. | Locomotor trajectories from the visual cliff test [3]. | Wild-type and retinal degenerative (rd1-2J) mice [3]. |
| Viral Metagenomics | Discover and classify novel viral pathogens [25]. | Viral protein family membership. | Amino acid or nucleotide sequences from metagenomic data [25]. | Profile HMMs from databases like vFam, pVOGs, and IMG/VR [25]. |
A primary ecological application involves using HMMs with GPS and IMU (Inertial Measurement Unit) data to classify animal behavior. Studies on albatrosses have successfully identified major movement modes—'flapping flight', 'soaring flight', and 'on-water'—with an overall model accuracy of 92% [19]. Similarly, research on red-billed tropicbirds demonstrated that incorporating a small subset of data from auxiliary sensors (e.g., wet-dry sensors, accelerometers) to semi-supervise HMMs significantly improved overall behavioral classification accuracy from 0.77 ± 0.01 to 0.85 ± 0.01 (mean ± sd) [18].
In biomedicine, HMMs provide sensitive measures of functional recovery in disease models. A landmark study on retinal degeneration in mice used an HMM to analyze behavior in a visual cliff test. The model identified three behavioral states (Resting, Exploring, and Navigating) and revealed that wild-type mice exhibited a strong cliff avoidance response, which habituated over trials, leading to a state collapse from three states to two [3]. Following retinal organoid transplantation, blind mice recovered a cliff avoidance response as early as two weeks post-transplantation, coinciding with early synapse formation. This robust response peaked at 16 weeks and later disappeared, accompanied by behavioral state collapse—a hallmark of adaptive learning and functional vision recovery [3].
Table 2: Quantitative Behavioral Metrics from HMM Analysis in Mouse Visual Cliff Test
| Behavioral Metric | Wild-Type (WT) Mice | Blind (RD) Mice | Transplanted RD Mice (Peak Response) |
|---|---|---|---|
| Initial Behavioral States | Three distinct states (Resting, Exploring, Navigating) [3]. | N/A | N/A |
| Cliff Avoidance Response | Strong initial response [3]. | No response [3]. | Robust response recovered [3]. |
| Behavioral Habituation | Rapid habituation and state collapse (3 → 2 states) [3]. | No habituation over time [3]. | State collapse observed by 18 weeks, similar to WT [3]. |
| Onset of Functional Recovery | N/A | N/A | 2 weeks post-transplantation [3]. |
Experimental Protocols
Protocol 1: HMM-Based Classification of Major Movement Modes from IMU Data
This protocol details the procedure for using HMMs to classify broad behavioral states like flapping flight, soaring flight, and on-water behavior in flying birds, as applied in albatross studies [19].
Research Reagent Solutions & Essential Materials
Table 3: Key Materials for Movement Ecology Protocol
| Item | Specification | Function |
|---|---|---|
| GPS/IMU Device | Includes tri-axial accelerometer and magnetometer (e.g., sampling at 25-75 Hz) [19]. | Records high-resolution movement and orientation data for behavioral inference. |
| Data Processing Software | MATLAB with Animal Tag Tools Wiki; R with moveHMM or momentuHMM packages [18] [19]. |
Processes raw sensor data, extracts features, and implements HMM fitting and decoding. |
| Computing Hardware | Computer with sufficient RAM and processing power for large high-frequency datasets [19]. | Handles computationally intensive data processing and model fitting. |
Step-by-Step Procedure
Device Deployment and Data Collection:
- Deploy GPS/IMU devices on the study animals, ensuring proper attachment to align the sensor axes (surge, sway, heave) with the animal's body axes [19].
- Program the devices to record data for the duration of a foraging trip or other relevant biological period.
Data Pre-processing and Calibration:
- Standardize Sampling Frequency: If necessary, decimate all data to a standard frequency (e.g., 25 Hz) [19].
- Calibrate Sensors: Transform the sensor data to align the device frame with the animal's body frame. Correct for any static orientation offsets using data from periods of known rest [19].
- Compute Movement Metrics: For GPS data, calculate step lengths (straight-line distance between consecutive locations) and turning angles (change in direction between steps) [18]. For accelerometer data, the overall dynamic body acceleration (ODBA) or static acceleration may be used as observed variables [19].
Exploratory Data Analysis and State Number Selection:
- Examine histograms of the observed data (e.g., step length, turning angle) to identify the number of distinct behavioral modes present.
- Based on ecological knowledge and data exploration, pre-define the number of hidden states (N) for the HMM (e.g., N=3 for "on-water", "soaring flight", "flapping flight") [19].
Model Fitting:
- Use an R package like
momentuHMMto fit an HMM to the prepared data series. - The model will estimate the initial state probabilities, the state transition probability matrix, and the state-dependent emission probability distributions (e.g., gamma distribution for step length, von Mises distribution for turning angle) [18].
- Use an R package like
State Decoding and Validation:
- Apply the Viterbi algorithm to the fitted HMM to determine the most probable sequence of hidden behavioral states for the entire observation sequence [26].
- Validate Model Output: Compare the HMM-inferred states with expert classifications identified from stereotypic patterns observed in the raw sensor data or from simultaneous video recordings to calculate accuracy [19].
Protocol 2: Assessing Visual Function Recovery in Murine Models Using HMMs
This protocol describes the use of HMMs to quantitatively assess depth perception and its recovery in mouse models of retinal degeneration, providing a sensitive metric for evaluating the efficacy of regenerative therapies [3].
Research Reagent Solutions & Essential Materials
Table 4: Key Materials for Visual Function Assessment Protocol
| Item | Specification | Function |
|---|---|---|
| Visual Cliff Apparatus | Table with high-contrast checkerboard pattern; transparent acrylic plate creating a "cliff" illusion; circular enclosure to minimize corner bias [3]. | Provides a standardized environment to test innate depth perception. |
| Video Tracking System | High-frame-rate camera (e.g., 30 fps) and pose estimation software (e.g., DeepLabCut) [3]. | Records and digitizes the mouse's locomotor activity for quantitative analysis. |
| Animal Model | Wild-type (WT) and retinal degenerative (e.g., rd1-2J) mice; cohorts receiving experimental interventions (e.g., retinal organoid transplantation) [3]. | Provides a model system to study visual function and its restoration. |
Step-by-Step Procedure
Apparatus Setup and Calibration:
- Set up the visual cliff apparatus in a room with uniform, controlled overhead lighting (e.g., 3000 K, 65 cd/m²) to ensure consistent visual cues and minimize shadows [3].
- Confirm the stability and safety of the transparent acrylic plate.
Behavioral Recording:
- At the start of each trial, place a single mouse on the central platform facing the shallow side.
- Allow the mouse to explore the apparatus freely for a set period (e.g., 10 minutes). Record the session from above using a video camera [3].
Motion Capture and Trajectory Extraction:
- Use deep learning-based software like DeepLabCut to track the body center coordinates (x, y) of the mouse across all video frames [3].
- Filter the tracking data to exclude frames with low confidence (e.g., below 90%) and downsample if necessary to reduce computational load.
Movement Metric Calculation:
- From the positional data, calculate the primary movement metrics for analysis:
- Step length (lₜ): The Euclidean distance between body center coordinates in consecutive frames [3].
- Turning angle: The change in direction of movement between steps.
- From the positional data, calculate the primary movement metrics for analysis:
HMM Fitting and State Identification:
- Fit an HMM to the sequence of derived movement metrics, typically using the first 3 minutes of the trial to assess the initial response [3].
- Define the model to infer three core behavioral states: Resting (little movement), Exploring (shorter steps, higher tortuosity), and Navigating (longer, more directed steps) [3].
Analysis of State Transitions and Cliff Response:
- Analyze the sequence of states, paying particular attention to transitions near the cliff boundary.
- Quantify the cliff avoidance response by comparing the probability of state transitions (e.g., from Navigating to Resting) when the mouse approaches the cliff edge versus the shallow side.
- Track changes in behavioral state structure (e.g., state collapse from three states to two) over repeated trials as a measure of habituation and functional integration [3].
Implementing HMMs: From Data Collection to Behavioral Classification
The accurate classification of animal behavior using hidden Markov models (HMMs) relies fundamentally on the quality and characteristics of the input sensor data. This protocol outlines the essential data requirements—encompassing sensor types, sampling rates, and tracking technologies—for researchers applying HMMs to animal movement and behavior analysis. The integration of precise data collection with robust modeling frameworks enables the identification of behavioral states from tracking data, facilitating advances in ecology, conservation, and drug development research.
Sensor Technologies for Data Acquisition
A variety of sensor technologies can be deployed on animals to collect movement data, each offering distinct advantages for capturing different aspects of behavior.
Table 1: Animal-Borne Sensor Technologies for Behavioral Studies
| Sensor Type | Primary Measurements | Common Applications in Behavior | Considerations |
|---|---|---|---|
| GPS/GNSS [27] | Animal position (longitude, latitude), sometimes altitude | Large-scale movement, habitat selection, travel paths | Accuracy varies; power-intensive; limited indoor/dense canopy use |
| Accelerometer [27] [28] [29] | Dynamic body acceleration (all three axes) | Fine-scale behaviors (grazing, running, resting), energy expenditure | High data volume; placement on body critical for signal interpretation |
| Gyroscope [29] | Angular velocity, orientation | Body rotation, turning angles, complex maneuvers | Complements accelerometer data for detailed movement reconstruction |
| Magnetometer | Heading, direction | Directional persistence, path tortuosity | Can be interfered with by local magnetic anomalies |
| Animal-Borne Video | Visual record of environment and animal actions | Direct validation of behaviors, context-aware analysis | Very high data load; limited battery life; privacy/ethical considerations |
| Bio-logger (Multi-sensor) [29] | Combination of above (e.g., ACC, GPS, Gyro, Env. sensors) | Comprehensive behavioral ethogram construction | Provides richest data source; requires sensor fusion techniques |
Sampling Rate Requirements and Data Collection Principles
The selection of an appropriate sampling frequency is critical to capturing meaningful behavioral signals without unnecessarily exhausting device power and storage.
The Nyquist-Shannon Theorem in Practice
A foundational principle in data acquisition is the Nyquist-Shannon sampling theorem, which states that the sampling frequency should be at least twice the frequency of the fastest body movement essential to characterize the behavior of interest [28]. Sampling below this Nyquist frequency results in aliasing, a distortion that misrepresents the original signal and can lead to misclassification of behaviors.
Species- and Behavior-Specific Sampling Rates
The optimal sampling rate is not universal; it depends on the specific behaviors under investigation.
Table 2: Behavior-Dependent Accelerometer Sampling Rate Guidelines
| Behavioral Characteristic | Example Behaviors | Recommended Minimum Sampling Rate | Evidence |
|---|---|---|---|
| Short-Burst, High-Frequency | Swallowing in birds, escape maneuvers in fish | 100 Hz (or 1.4x Nyquist frequency) | Pied flycatcher swallowing occurred at ~28 Hz, requiring ~100 Hz for accurate classification [28]. |
| Long-Endurance, Rhythmic | Flight in birds, steady swimming in fish | 12.5 Hz (or equal to Nyquist frequency) | Flight in pied flycatchers was adequately characterized at 12.5 Hz [28]. |
| Common Livestock Activities | Lying, walking, standing in sheep | 16-32 Hz | Classification performance for sheep showed best results at 32 Hz, with marginal gains beyond 16 Hz [28]. |
Data Collection Protocol for HMM Training
To collect high-quality data for training and validating HMMs, follow this experimental workflow:
- Hypothesis and Ethogram Definition: Define the specific behavioral states to be classified (e.g., "encamped" vs. "exploratory," "foraging" vs. "traveling") [17] [29].
- Sensor Selection and Configuration:
- Select a biologger that includes an accelerometer and, if needed for spatial context, a GPS.
- Set the accelerometer sampling rate based on the fastest behavior of interest, following the guidelines in Table 2. When in doubt, oversample (e.g., 50-100 Hz).
- Set the GPS fix rate according to the scale of movement. For fine-scale habitat selection, higher frequencies (e.g., 1 Hz) may be needed, whereas for large-scale migration, lower frequencies (e.g., every 5-15 minutes) suffice [30].
- Sensor Deployment:
- Ground-Truthing and Data Annotation:
- Simultaneously record the animal's behavior using video surveillance (e.g., high-speed cameras) or direct visual observation during controlled experiments or periods of the deployment [28] [29].
- Annotate the sensor data stream with the observed behaviors to create a labeled dataset for model training. This is the "ground truth" against which the HMM's predictions will be compared.
- Data Synchronization: Precisely synchronize the clocks on all sensors and video recording equipment to enable accurate matching of sensor data to observed behaviors.
Integrating Sensor Data with Hidden Markov Models
HMMs are powerful tools for identifying latent (unobserved) behavioral states from observed sensor data. The data collection protocols above are designed to feed directly into these models.
The HMM Framework for Behavior Classification
An HMM assumes that an animal is, at any time, in one of a finite number of hidden behavioral states. The state sequence is a Markov process, and the observations (sensor data) are probabilistic functions of the underlying state [15] [17].
From Raw Data to Model Input
The path from raw sensor data to HMM analysis involves several key steps, which can be visualized in the following workflow.
Data Analysis Workflow for HMMs
- Data Preprocessing: Clean the raw data by removing erroneous GPS fixes and sensor artifacts. For accelerometer data, calculate metrics like the vector of dynamic body acceleration (VeDBA) or Overall Dynamic Body Acceleration (ODBA) which serve as proxies for energy expenditure and movement intensity [28] [29].
- Movement Feature Extraction: From the GPS and/or accelerometer data, derive movement characteristics that are informative for behavior. Common features include:
- Step Length: The distance between consecutive locations.
- Turning Angle: The change in direction between successive steps.
- Speed: The rate of movement.
- HMM-SSF Integration: For a more powerful, spatially explicit analysis, implement an Integrated HMM-Step Selection Function (HMM-SSF) [17]. This model uses an HMM where the observation process is defined by an SSF, allowing states to be classified based on both movement mechanics (step length, turning angle) and habitat selection. This jointly estimates the behavioral state and the habitat preferences associated with each state.
- State Decoding: Use the fitted HMM and the forward-backward algorithm to compute the most probable sequence of behavioral states that generated the observed sensor data [17].
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Reagents and Solutions for Tracking and Behavior Analysis
| Item / Solution | Function / Application | Example Use Case |
|---|---|---|
| Bio-logger (Multi-sensor) [29] | Records time-series data (ACC, GPS, etc.) from free-moving animals. | Core data collection device deployed on animals in the field or lab. |
| AlphaTracker Software [31] | Markerless pose estimation and tracking of multiple, identical animals from video. | Provides ground-truth location and keypoint data for lab-based social behavior studies. |
| BEBE Benchmark [29] | A public benchmark of labeled bio-logger data for validating behavior classification models. | Evaluating and comparing the performance of new HMMs and other ML algorithms. |
| MoveHMM / MomentuHMM R Packages | Statistical software for fitting HMMs to animal tracking data. | Implementing the HMM analysis, including state decoding and parameter estimation. |
| Self-Supervised Learning Models [29] | Models pre-trained on large, unlabeled datasets (e.g., human accelerometer data). | Transfer learning to improve HMM performance on a target species with limited labeled data. |
| Kalman Filter [31] | An algorithm that estimates the true state of a system from noisy measurements. | Smoothing noisy GPS or keypoint tracking data before HMM analysis. |
Within research focused on classifying animal behavior using hidden Markov models (HMMs), the integrity of the model's input is paramount. A robust preprocessing pipeline that transforms raw location data into meaningful movement features is a critical first step, directly influencing the HMM's capacity to identify distinct behavioral states [32]. This document outlines detailed protocols for converting raw tracking data into analyzed-ready features, providing a standardized methodology for researchers in neuroscience and drug development.
Experimental Protocols & Workflow
The following protocol details the sequential steps from video recording to the generation of movement features suitable for HMM analysis.
Stage 1: Video Acquisition and Preprocessing
- Objective: To obtain high-quality video data amenable to automated tracking.
- Procedure:
- Record Behavior: Capture animal behavior using a high-resolution camera mounted orthogonally to the experimental arena to minimize perspective distortion.
- Decompose Video: Split the video file into individual, sequential frames. The frame rate should be sufficient to capture the behaviors of interest (e.g., 30 frames per second).
- Generate Live-Frames (Optional but Recommended): To incorporate temporal motion information, create "live-frames" by stacking three consecutive grayscale frames into a single RGB image, where each channel represents the animal's position at a different time point [33]. This creates a motion-colored image that preserves spatial and temporal information.
Stage 2: Animal Pose Tracking with DeepLabCut
- Objective: To extract precise, time-series data of animal body part locations from video frames.
- Procedure:
- Install DeepLabCut: Install the DeepLabCut package in a Python environment following the official documentation.
- Define Body Parts: Label key body parts (e.g., snout, ears, tail base, limbs) relevant to the study. For social behaviors, label body parts on all animals [32].
- Create a Training Dataset: Manually annotate the defined body parts across a diverse set of frames extracted from the videos. This "labels" the data for the model.
- Train the Network: Use the annotated dataset to train a deep neural network within DeepLabCut to recognize and track the body parts in new, unlabeled video data.
- Analyze Videos: Process the full behavior videos through the trained DeepLabCut network to obtain the estimated X, Y coordinates (and likelihood) for each defined body part in every frame [32].
- Extract Track Data: Export the resulting tracking data, typically as a CSV or HDF5 file, for further processing. The output is a table of raw location data across time.
Stage 3: Data Cleaning and Smoothing
- Objective: To address tracking errors and noise in the raw location data.
- Procedure:
- Handle Low-Likelihood Points: Identify tracked points with a low estimation likelihood (below a set threshold, e.g., 0.95). Replace these coordinates using interpolation from high-likelihood neighboring frames.
- Apply Smoothing Filters: Use a Savitzky-Golay filter or a Gaussian kernel to smooth the X and Y trajectories. This reduces high-frequency noise from tracking jitter while preserving the underlying movement dynamics.
Stage 4: Movement Feature Engineering
- Objective: To transform smoothed location data into a set of discriminative features that describe the animal's behavior.
- Procedure:
For each animal and each time point, calculate the following features from the smoothed X, Y coordinates:
- Velocity: The speed of movement, calculated as the Euclidean distance between positions in consecutive frames, divided by the inter-frame interval.
- Acceleration: The rate of change of velocity.
- Angular Velocity: The rate of change of the direction of movement (heading angle).
- Body Length: The distance between two body points (e.g., snout and tail base) to estimate posture.
- Nose-Tailbase Angle: The angle formed by three points (e.g., snout, center of mass, tail base) to capture body curvature.
- Social Features (Multi-Animal): Calculate inter-animal distance, relative orientation, and approach/retreat speeds.
The final output is a feature matrix where each row represents a time point and each column represents a calculated movement feature. This matrix is the direct input for HMM analysis.
Quantitative Data Presentation
The following table summarizes the core movement features engineered from raw location data. These features serve as the observables for the HMM.
Table 1: Engineered Movement Features from Animal Tracking Data
| Feature Category | Feature Name | Calculation Method | Behavioral Significance |
|---|---|---|---|
| Locomotion | Velocity | (\frac{\sqrt{(X{t}-X{t-1})^2 + (Y{t}-Y{t-1})^2}}{\Delta T}) | General activity level; running vs. resting |
| Acceleration | (\frac{Velocity{t} - Velocity{t-1}}{\Delta T}) | Movement bursts and sudden stops | |
| Angular Velocity | (\frac{Heading{t} - Heading{t-1}}{\Delta T}) | Meandering vs. directed movement | |
| Posture | Body Length | Distance between snout and tail base | Stretching, contracting, or freezing |
| Nose-Tailbase Angle | Angle formed by snout, center-of-mass, and tail base | Body curvature during turning or grooming | |
| Social | Inter-Animal Distance | Euclidean distance between two animals' centers-of-mass | Proximity and social interaction |
| Relative Orientation | Angle between the heading angles of two animals | Facing, following, or parallel movement |
Workflow Visualization
The following diagram illustrates the complete pipeline from data acquisition to HMM classification.
From Features to Behavioral States
The next diagram conceptualizes how the generated feature matrix is used by a Hidden Markov Model to infer latent behavioral states.
The Scientist's Toolkit
Table 2: Essential Research Reagents and Tools for Behavioral Tracking and Analysis
| Tool / Reagent | Function in the Pipeline | Key Considerations |
|---|---|---|
| DeepLabCut [32] | Open-source tool for markerless pose estimation based on deep learning. Extracts raw body part coordinates from video frames. | Requires a Python environment and initial manual labeling of a training dataset. Highly customizable. |
| Selfee [33] | A self-supervised convolutional neural network for end-to-end feature extraction directly from video frames, without the need for pose estimation. | Useful when detailed postures are hard to extract or for multi-animal interactions. Provides "meta-representations." |
| Circular Behavioral Arena [32] | An apparatus for housing animals during video recording. A circular design eliminates corner preferences, promoting more natural exploration and unbiased data collection. | Critical for visual cliff tests and other experiments where spatial bias can confound results. |
| Hidden Markov Model (HMM) | A statistical model that identifies latent (hidden) behavioral states from a time-series of observed movement features. Models state transitions and durations. | The choice of model (e.g., AR-HMM) and number of states must be validated for the specific behavior and species. |
In animal movement ecology, Hidden Markov Models (HMMs) have emerged as a powerful statistical framework for identifying discrete behavioral states from tracking data. These models assume that observed movement patterns (e.g., step lengths, turning angles) are generated by underlying, unobservable behavioral states that follow a Markov process [1] [34]. The core concept involves a double stochastic process where latent behavioral states evolve according to transition probabilities, while observations depend probabilistically on these hidden states through state-dependent distributions [15] [35]. This approach has been successfully applied across diverse species including grey seals, lake trout, blue sharks, and laboratory mice, demonstrating its versatility for classifying behaviors such as resting, foraging, exploration, and transit [15] [32].
Quantitative Specification of Behavioral States
Mathematical Foundation
The HMM framework consists of two primary components: the state process and the observation process. The state process is defined as a Markov chain with transition probabilities between discrete behavioral states, while the observation process links these hidden states to measurable movement metrics [15] [34]. The joint density function for an HMM can be expressed as:
[p(\mathbf{z}{1:T} \mid \mathbf{x}{1:T}) = p(\mathbf{z}{1:T}) p(\mathbf{x}{1:T} \mid \mathbf{z}{1:T}) = \left[ p(z1) \prod{t=2}^{T} p(zt \mid z{t-1}) \right] \left[ \prod{t=1}^T p(\mathbf{x}t \mid zt) \right]]
where (zt) represents the hidden behavioral state at time (t), and (\mathbf{x}t) represents the observations [34]. The model is characterized by three fundamental elements: the initial state distribution (\delta), the state transition probability matrix (A), and the state-dependent observation distributions [15] [35].
Characteristic State Signatures
Table 1: Quantitative Characteristics of Common Behavioral States in Animal Movement
| Behavioral State | Step Length Characteristics | Turning Angle Characteristics | Biological Interpretation | Typical Parameter Values |
|---|---|---|---|---|
| Resting | Short steps with minimal displacement | Irregular or undirected turning angles | Energy conservation, digestion, vigilance | (\gamma < 0.3), high variance in step length |
| Exploring/Foraging | Intermediate steps with high variance | High tortuosity, frequent course reversals ((\theta \approx \pi)) | Area-restricted search, resource exploitation | (\gamma = 0.3-0.5), (\theta \approx \pi) |
| Transit/Navigating | Long, persistent steps with low variance | Directed movement with minimal turning ((\theta \approx 0)) | Directed travel between habitats, migration | (\gamma > 0.5), (\theta \approx 0), (\sigma^2) low |
The discrimination between behavioral states is primarily achieved through differences in movement parameters including autocorrelation in speed and direction ((\gamma)), turning angle distributions ((\theta)), and stochasticity in movement ((\Sigma)) [15]. These parameters are typically estimated using maximum likelihood methods implemented through specialized R packages such as momentuHMM, swim, or moveHMM [15] [36].
Experimental Protocol for Behavioral State Classification
Data Collection and Preprocessing
Animal Tracking: Deploy appropriate telemetry technology (GPS, acoustic telemetry, satellite tags) to collect high-resolution positional data. The specific technology should be selected based on species characteristics and research environment [15].
Movement Metric Calculation: From raw location data, calculate step lengths (straight-line distances between consecutive locations) and turning angles (changes in direction between successive steps). For 2D movement data, these are derived from first differences of locations: (\mathbf{d}t = \mathbf{x}t - \mathbf{x}_{t-1}) [15].
Data Cleaning: Address missing positions, measurement error, and irregular time intervals using interpolation or state-space approaches where necessary. The
momentuHMMpackage provides functionality for handling these common data issues [36].
Model Specification and Implementation
State Number Selection: Determine the appropriate number of behavioral states ((K)) based on biological knowledge, model selection criteria (AIC, BIC), or through preliminary analysis of movement patterns. Most applications utilize 2-4 behavioral states [32].
Initial Parameter Estimation: Provide initial values for state transition probabilities and parameters of state-dependent distributions (typically gamma distributions for step lengths and von Mises distributions for turning angles). These can be informed by visual inspection of movement tracks or preliminary clustering [35].
Model Fitting: Implement the HMM using specialized software. The following code demonstrates basic implementation using the
momentuHMMpackage in R:
- Model Validation: Assess model fit through pseudo-residual analysis, examination of decoding uncertainties, and comparison of predicted versus observed movement patterns [15] [36].
State Decoding and Interpretation
Global Decoding: Apply the Viterbi algorithm to determine the most likely sequence of behavioral states given the observations and fitted model parameters [1] [34].
Local Decoding: Calculate the marginal probabilities of each behavioral state at each time point using the forward-backward algorithm, providing a measure of classification certainty [1].
Biological Validation: Correlate identified behavioral states with independent biological data (e.g., feeding events, environmental context, physiological measurements) to ensure ecological relevance of the classification [32].
HMM Architecture for Behavioral Classification
HMM Behavioral State Diagram: This architecture illustrates the relationship between hidden behavioral states (Resting, Exploring, Transit) and observed movement metrics in animal tracking data. The state transition probabilities ((a{ij})) govern switches between behavioral states, while emission probabilities ((bi(observation))) link each state to characteristic distributions of step lengths and turning angles.
Essential Research Toolkit
Table 2: Essential Research Reagents and Computational Tools for HMM Implementation
| Tool/Resource | Specific Function | Application Context | Implementation Source |
|---|---|---|---|
| momentuHMM R Package | Maximum likelihood analysis of animal movement using multivariate HMMs | Handling complex telemetry data with multiple behavioral states, missing data, and measurement error | [36] |
| moveHMM R Package | Basic HMM framework for animal movement data | Standard step length and turning angle analysis with 2-3 behavioral states | [15] |
| swim R Package | Implementation of HMMM (Hidden Markov Movement Model) | Rapid analysis of highly accurate tracking data with negligible measurement error | [15] |
| DeepLabCut | Markerless pose estimation from video recordings | Extracting precise movement metrics from visual data in controlled environments | [32] [10] |
| TMB (Template Model Builder) | Maximum likelihood estimation of HMM parameters | Efficient parameter estimation for complex movement models with random effects | [15] |
| Baum-Welch Algorithm | Estimation of HMM parameters from observed data | Model fitting when initial state sequences are unknown | [35] |
| Viterbi Algorithm | Global decoding of the most likely state sequence | Identification of the optimal behavioral state path given observations | [1] [34] |
Advanced Methodological Considerations
Covariate Integration
Environmental covariates (temperature, habitat type, time of day) can be incorporated into HMMs to explain variation in both transition probabilities and state-dependent distributions. This is typically achieved through multinomial logit links for transition probabilities and parametric relationships in observation distributions [36].
Hierarchical Extensions
Hierarchical HMMs allow for individual-level variability in movement parameters while estimating population-level distributions, making them particularly valuable for studies with multiple individuals or groups [36].
Measurement Error Handling
For tracking technologies with significant measurement error (e.g., Argos satellite telemetry), state-space model extensions of HMMs can be implemented to simultaneously account for observation error and behavioral classification [15].
The visual cliff test, originally developed by Gibson and Walk, is a foundational paradigm for assessing depth perception in animals [37]. This test ingeniously creates the illusion of a sharp drop-off ("the cliff") using a transparent surface, allowing researchers to investigate an animal's innate response to visual depth cues without the risk of actual falling. Traditionally, the analysis of this behavior has relied on simple metrics, such as the time an animal spends on the "shallow" versus the "deep" side of the apparatus [38].
However, recent advancements in computational ethology have revolutionized this classic test. The integration of high-resolution movement tracking with Hidden Markov Models (HMMs) now enables a far more nuanced dissection of behavior [32] [3]. This modern approach moves beyond simplistic measures to model behavior as a dynamic sequence of hidden, or latent, states. These states—such as Resting, Exploring, and Navigating—generate the observable movements of the animal [3] [10]. This case study details how this powerful combination of a modified visual cliff apparatus and HMM-based analysis provides a sophisticated framework for studying visual perception in mice, with direct applications in evaluating visual function, modeling human visual diseases, and screening the efficacy of novel therapeutic agents.
Theoretical Background
The Original Visual Cliff Paradigm
The classic visual cliff experiment was designed to determine if depth perception is innate or learned. The apparatus consists of a central board raised to a moderate height, covered by a transparent glass surface. On one side (the "shallow" side), a textured pattern is placed directly beneath the glass. On the other side (the "deep" side), the identical pattern is placed on the floor far below the glass, creating the visual illusion of a cliff [37].
Seminal studies found that 92% of human infants (6-14 months old) refused to crawl onto the deep side when called by their mothers, suggesting an early ability to perceive depth [37]. Similar innate avoidance behaviors were observed in various terrestrial species like chicks, lambs, and kids, all of which avoided the deep side from the first day of life [37]. This established the visual cliff as a valid tool for investigating the nativist perspective on depth perception.
Hidden Markov Models for Behavioral Classification
A Hidden Markov Model (HMM) is a statistical model that is particularly suited for analyzing time-series data where the system being studied is assumed to be a Markov process with unobserved (hidden) states.
- Core Concept: The model posits that an animal's behavior can be described as being in one of a finite number of discrete, hidden behavioral states at any given time. The key is that these states themselves are not directly observed; instead, we observe the animal's movement metrics (like step length and turning angle), which are emitted by these hidden states.
- State Transitions: The model calculates the probability of transitioning from one behavioral state to another (e.g., from "Resting" to "Exploring").
- Emission Probabilities: Each hidden state is characterized by a probability distribution over the observable movement metrics. For example, the "Resting" state would have a high probability of emitting a very short step length, while the "Navigating" state would have a high probability of emitting long step lengths and low turning angles [3] [18].
Applied to the visual cliff test, HMMs can identify how an animal's underlying behavioral state is modulated by its perception of a visual cliff, offering a dynamic and probabilistic view of behavior that traditional methods cannot capture.
Modernized Experimental Protocol
This protocol details the setup and procedure for a contemporary visual cliff experiment using a circular apparatus and HMM-based analysis [32] [3] [10].
Apparatus and Materials
The transition from a square to a circular apparatus is a critical modification that minimizes corner-seeking behavior in mice, promoting more natural exploration and increasing valid interactions with the cliff edge [32] [10].
Table 1: Essential Research Reagents and Equipment
| Item Name | Specifications / Function |
|---|---|
| Visual Cliff Apparatus | Circular enclosure (e.g., 60 cm inner diameter) placed on a transparent acrylic sheet (1 m x 1 m x 5 mm thickness) overhanging a high-contrast checkerboard pattern [3] [10]. |
| Checkerboard Pattern | High-contrast (1:0 black-white) pattern; optimal square size for mice is 2-8 cm [32] [3]. |
| Overhead Lighting | Uniform, 3000K temperature, ~65 cd/m² intensity to simulate dawn/dusk conditions when mice are most active [3]. |
| High-Speed Camera | Mounted directly above the apparatus; records at ≥30 frames per second for subsequent tracking [3]. |
| Tracking Software | DeepLabCut (DLC): An open-source deep learning tool for precise, markerless tracking of body part coordinates from video data [32] [10] [39]. |
| HMM Analysis Pipeline | Custom scripts (e.g., in R or Python using packages like momentuHMM) to process DLC tracking data and fit Hidden Markov Models [32] [18]. |
Experimental Procedure
- Apparatus Setup: Ensure the acrylic plate is clean and the checkerboard pattern is correctly positioned. Provide uniform overhead illumination. The central starting platform should be aligned with the boundary between the shallow and deep sides [3].
- Animal Acclimation: House mice on a reverse 12-hour light/dark cycle. Conduct all experiments during the early subjective morning (2 hours before the end of the dark period) to capitalize on the animals' natural crepuscular activity peaks [3].
- Behavioral Testing: Gently place a single mouse on the central platform, facing the shallow side. Allow the animal to explore the apparatus freely for a defined test period (e.g., 10 minutes) without any experimenter interference. The entire session is recorded from above using a high-speed camera [3] [38].
- Data Acquisition (Pose Estimation): Use DeepLabCut to analyze the recorded videos. Train a model (if necessary) to identify key body points, such as the nose, ears, and body center. The primary output for initial analysis is the time series of the animal's body center coordinates (x, y) across frames [3] [10].
- Movement Metric Calculation: From the body center coordinates, calculate two primary movement metrics for each time interval (e.g., 0.1s):
- Step Length (
l_t): The Euclidean distance traveled between consecutive frames:l_t = √[(x_t - x_{t-1})² + (y_t - y_{t-1})²][3]. - Turning Angle (
θ_t): The change in direction relative to the previous movement vector.
- Step Length (
HMM Implementation and Behavioral State Classification
The processed movement data is used to fit an HMM, typically with three states for this context [32] [3]:
- Data Preparation: Compile the step lengths and turning angles into a matrix for input into the HMM analysis software.
- Model Fitting: Fit an HMM to the data from all animals. The model will learn the initial state probabilities, the state transition probability matrix, and the state-dependent emission distributions for step length and turning angle.
- State Decoding: Use the Viterbi algorithm to determine the most likely sequence of hidden behavioral states (
Resting,Exploring,Navigating) for each animal throughout its trial, based on its observed movement track [18].
Table 2: Defining Characteristics of HMM-Derived Behavioral States
| Behavioral State | Step Length | Turning Angle | Behavioral Manifestation |
|---|---|---|---|
| Resting | Very short or zero | Variable, often high due to GPS/camera error | Stationary, with minimal movement; grooming or inactivity. |
| Exploring | Short to medium | High variance, tortuous path | Slow, investigative movement with frequent changes in direction. |
| Navigating | Long | Low variance, directed path | Fast, purposeful, and directional locomotion. |
The following diagram illustrates the logical structure of the HMM and the workflow of the experiment, from data collection to state inference.
Figure 1: Experimental and HMM Analysis Workflow
Key Findings and Applications
Validation of the HMM Approach
Studies comparing wild-type (WT) mice with retinal degeneration models (RD, e.g., rd1-2J mice) confirm the sensitivity of the HMM-based visual cliff test. WT mice consistently display a strong cliff avoidance response, characterized by fewer entries and less time spent on the deep side. This is reflected in their HMM state transitions, such as a high probability of transitioning from Navigating to Resting or Exploring when approaching the cliff edge. In contrast, RD mice, which lack functional vision, show no such avoidance and distribute their behavior randomly across the apparatus, with state transitions unaffected by the cliff boundary [32] [3].
Quantifying Recovery of Visual Function
The HMM framework is exceptionally valuable for tracking the recovery of visual function in disease models following therapeutic intervention.
- Post-Transplantation Recovery: In
rd1-2Jmice that received retinal organoid transplants, HMM analysis detected the emergence of a cliff avoidance response as early as two weeks post-transplantation. This behavioral recovery coincided with early synapse formation between grafted photoreceptors and host bipolar cells. - Temporal Dynamics: The avoidance behavior became most robust at 16 weeks and, notably, disappeared again by 18 weeks. This later disappearance was accompanied by "state collapse"—a reduction from three distinct behavioral states to two—which is a hallmark of habituation previously observed only in sighted WT mice. This pattern indicates not just sensory recovery but also the restoration of adaptive learning, where the mouse learns the cliff is not a real threat [3].
The following diagram visualizes these critical state transitions in response to the visual cliff stimulus across different mouse models.
Figure 2: Behavioral State Transitions at the Cliff Edge in WT Mice
Advantages Over Traditional Analysis
Table 3: Comparison of Traditional vs. HMM-based Visual Cliff Analysis
| Analysis Feature | Traditional Method | HMM-Based Method |
|---|---|---|
| Primary Metrics | Time in zones, number of crossings [38]. | Sequence of latent behavioral states (Resting, Exploring, Navigating) [32] [3]. |
| Temporal Resolution | Static, aggregate measures over the entire trial. | Dynamic, captures moment-to-moment transitions and evolution of behavior [32]. |
| Sensitivity | Low; can be confounded by non-visual factors like corner preference and general anxiety. | High; distinguishes visually-guided behavior from general exploration, even detecting habituation [32] [3]. |
| Information Depth | Answers "what" the animal did (e.g., avoided the deep side). | Infers "how" and "when" the animal modulated its behavior in response to the stimulus [10]. |
| Application in Therapy | Can only detect gross restoration or loss of function. | Can detect subtle, incremental recovery and complex adaptive processes like re-learning [3]. |
The integration of the classic visual cliff paradigm with modern computational tools represents a significant leap forward in behavioral neuroscience. By applying Hidden Markov Models to high-resolution tracking data, researchers can move beyond simplistic, binary readouts to access a rich, dynamic landscape of animal behavior. This approach allows for the sensitive quantification of visual perception, the detection of subtle therapeutic effects in disease models, and a deeper understanding of how sensory information is integrated into adaptive motor control. For researchers and drug development professionals, this HMM-based framework provides a robust, quantitative, and highly informative platform for preclinical assessment of visual function and the efficacy of vision-restoring therapies.
Hidden Markov Models (HMMs) have emerged as a powerful statistical framework for inferring unobserved behavioral states from animal movement data. Within movement ecology, HMMs are particularly valuable for classifying latent behavioral modes—such as foraging, traveling, and resting—based on observed movement patterns like step lengths and turning angles derived from tracking data [15] [40]. This case study details the application of HMMs to investigate the foraging ecology and state-dependent movement of marine predators, providing a practical guide for researchers. The protocols herein are framed within a broader thesis on advanced behavioral classification from telemetry data.
Theoretical Foundation: HMMs in Movement Ecology
In the context of animal movement, a HMM is defined by two intertwined stochastic processes:
- A latent state sequence (S₁, ..., S_T), representing the behavioral modes, which form a Markov chain.
- An observed sequence (X₁, ..., XT), representing the movement metrics (e.g., step length and turning angle), whose distribution at time *t* depends on the underlying state *St* [15] [40].
The model is characterized by:
- State transition probabilities, γᵢⱼ = Pr(S_t = j | S_{t-1} = i), defining the probability of switching from state i to state j.
- State-dependent distributions, defining the probability of an observation X_t given the state S_t, e.g., f(X_t | S_t = j) [15].
For marine predators, this typically translates to identifying two or three core behavioral states:
- State 1: Transit - characterized by long step lengths and low turning angles, indicating directed, energy-efficient travel.
- State 2: Foraging - characterized by short, variable step lengths and high turning angles, representing area-restricted search (ARS) and prey capture attempts [41] [42].
- State 3: Resting - (if present) characterized by very short or zero step lengths.
The connection between movement behavior and foraging effort has been validated in several marine predator studies. For example, in baleen whales, lower "move persistence" (a continuous metric analogous to the tortuosity of the HMM's foraging state) was strongly correlated with a higher rate of feeding dives [43]. Similarly, a study on northern gannets found that areas identified as "search behavior" by HMMs contained 81% of all recorded dive events [44].
Table 1: Core Behavioral States in Marine Predator HMMs
| Behavioral State | Movement Signature | Ecological Interpretation |
|---|---|---|
| Transit / Directed Movement | Long step lengths, low turning angles [15] [42] | Directed travel between patches; migration |
| Foraging / Area-Restricted Search | Short, variable step lengths; high turning angles [41] [42] | Searching for and capturing prey |
| Resting | Very short or zero step lengths [42] | Energy recovery; digestion |
Experimental Protocols
Data Collection and Pre-processing
Objective: To collect and prepare high-resolution animal tracking data for HMM analysis.
Materials:
- Animal-borne biologging tags (e.g., GPS, Argos satellite transmitters, time-depth recorders, accelerometers).
- Data processing software (e.g., R, Python).
Procedure:
- Tag Deployment: Deploy telemetry tags on the study species. Ensure tag programming (e.g., fix intervals, sensor sampling rates) aligns with the research question. For foraging studies, a higher resolution (e.g., 2-30 minutes between GPS fixes) is preferable [43] [45].
- Data Retrieval & Cleaning: Download raw location data. Remove 2D and 3D locations with high error (e.g., Argos location classes Z, B, A, or dilution of precision values >7) [43] [42].
- Track Regularization: Use a state-space model (SSM) to account for observation error and interpolate locations to regular time intervals. The
foieGrasR package is a suitable tool for this [41]. - Movement Metric Calculation: From the regularized track, compute:
- Step length: The straight-line distance between consecutive locations.
- Turning angle: The change in direction between consecutive steps (in radians, range -π to π).
HMM Fitting and Behavioral Classification
Objective: To fit an HMM to the movement metrics and decode the most probable sequence of behavioral states.
Procedure:
- Model Specification:
- Choose the number of behavioral states (N), typically 2 or 3 to balance ecological interpretability and model complexity.
- Select state-dependent distributions. The Gamma distribution is standard for step lengths, and the von Mises distribution is standard for turning angles [42].
- Define initial parameter values for the distributions and the transition probability matrix.
- Model Fitting:
- Fit the HMM using the
momentuHMMpackage in R [42] or a similar tool. The model is typically fitted via maximum likelihood estimation using the forward algorithm. - For data with high temporal resolution (e.g., >1 Hz), consider an autoregressive HMM (AR-HMM) to account for within-state correlation caused by movement momentum [4].
- Fit the HMM using the
- State Decoding:
- Use the Viterbi algorithm to determine the most likely sequence of hidden behavioral states given the fitted model and the observed data [42].
Validation and Linking Behavior to Ecology
Objective: To validate the HMM-inferred behaviors and correlate them with environmental and prey data.
Procedure:
- Ground-Truthing (When Possible): Use supplemental data streams to validate inferred foraging behavior. This can include:
- Environmental Covariates: Integrate environmental data (e.g., sea surface temperature, chlorophyll-a concentration, bathymetry, modelled prey fields) into the HMM framework as covariates affecting the transition probabilities. This helps explain why animals switch behaviors [43] [41].
- Recursive Movement Analysis: Calculate revisitation rates and residence time to areas identified as foraging hotspots. The
recurseR package can be used for this analysis [42].
Figure 1: Workflow for analyzing marine predator foraging ecology using HMMs. The process flows from data collection through model fitting to ecological validation.
Case Application: Blue and Fin Whales in the California Current
A study on sympatric blue and fin whales exemplifies this protocol. Researchers used a 14-year satellite tagging dataset and applied move-persistence modeling (a continuous analogue of HMMs) to quantify movement directionality [43].
- Key Finding 1: Low move persistence (less directional movement, analogous to the HMM foraging state) was strongly correlated with a higher number of feeding dives recorded by sensor-equipped tags, validating the behavioral inference [43].
- Key Finding 2: Environmental drivers of foraging behavior were identified. For both species, foraging occurred more often in shallower waters and specific sea surface heights. Blue whales also foraged in areas of higher chlorophyll-a concentration and marine nekton biomass [43].
- Key Finding 3: The whales moved between different bioregions to exploit seasonal peaks in productivity, demonstrating how state-dependent movement scales up to influence broad-scale distribution [43].
Table 2: Key Findings from Blue and Fin Whale Foraging Study
| Research Aspect | Finding | Methodological Confirmation |
|---|---|---|
| Behavioral Validation | Low move persistence = Increased feeding dive rate [43] | Sensor tags (time-depth recorders) |
| Environmental Drivers | Foraging correlated with shallow depth, sea surface height, and (for blue whales) chl-a & prey biomass [43] | Integration of environmental covariates in movement models |
| Spatial Ecology | Movement across bioregions tracks seasonal productivity peaks [43] | Long-term satellite tracking & regional segmentation |
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials and Tools for HMM-Based Foraging Ecology
| Tool / Material | Function | Example Use Case |
|---|---|---|
| Satellite Transmitters | Provides large-scale movement data via systems like Argos or GPS [43] | Tracking migratory pathways and broad-scale habitat use in whales [43] |
| Time-Depth Recorders (TDR) | Records diving depth and duration [44] [45] | Validating HMM-inferred foraging states with dive profiles in seabirds and pinnipeds [44] |
| Accelerometers | Measures fine-scale body acceleration and posture [45] | Identifying prey capture attempts (e.g., lunges) and specific foraging behaviors [45] |
State-Space Model (SSM) R package foieGras |
Regularizes raw tracking data, accounts for measurement error [41] | Pre-processing location data before calculating step lengths and turning angles for HMMs [41] |
HMM R package momentuHMM |
Fits HMMs to animal tracking data, decodes behavioral states [42] | Classifying behavioral states from step lengths and turning angles for land and marine animals [42] |
Recursive Movement R package recurse |
Calculates revisitation rates and residence time to locations [42] | Analyzing fidelity to and time spent in identified foraging hotspots [42] |
This Application Note outlines a robust protocol for applying HMMs to decipher the foraging ecology of marine predators. The integration of high-resolution telemetry data, statistical HMM frameworks, and independent validation techniques enables researchers to move beyond simple occurrence maps and understand the behavioral state-dependent processes that underpin animal movement and resource selection. The case study on whales demonstrates the power of this approach to link behavior to environmental drivers, a critical step for predicting animal responses to environmental change.
Hidden Markov Models (HMMs) have become a fundamental tool for inferring latent animal behavioural states from observed tracking data [46]. A basic HMM characterizes the hidden state process, where the probability of an animal being in a particular behavioural state at time t depends only on its state at time t-1 (the Markov property) [46]. The observed data, such as movement metrics derived from tracking data (e.g., step lengths and turning angles), are modelled as arising from state-dependent distributions [46] [17].
Standard HMMs, which rely solely on movement metrics for state classification, are often inadequate for capturing the full complexity of animal behaviour. Animal behaviour is not only a function of internal state but is also profoundly influenced by the external environment. Incorporating environmental covariates and mixed effects into HMMs represents a significant methodological advancement, enabling researchers to answer more sophisticated ecological questions about the drivers of behaviour and individual variation in behavioural strategies [17]. This protocol details the implementation of these advanced extensions.
Core Methodological Framework
The HMM-SSF Integrated Model
A powerful framework for incorporating environmental data is the integrated HMM with Step Selection Function (HMM-SSF) [17]. This model formulates the HMM's observation process using an SSF, which allows the probability of an observed movement step to be jointly determined by both movement mechanics and habitat selection.
In this integrated model, the likelihood of a step ending at location (\mathbf{y}{t+1}) given it started at (\mathbf{y}t) and that the animal is in behavioural state (s_t) is given by:
[ p(\mathbf{y}{t+1} \mid \mathbf{y}t, st) = \frac{w(\mathbf{y}t, \mathbf{y}{t+1}, st) \phi(\mathbf{y}{t+1} \mid \mathbf{y}t, st)}{\int{\mathbf{z} \in \Omega} w(\mathbf{y}t, \mathbf{z}, st) \phi(\mathbf{z} \mid \mathbf{y}t, st) d\mathbf{z}} ]
where:
- (\phi(\cdot)) is the movement kernel, defining possible steps and turns based on the behavioural state.
- (w(\cdot)) is the habitat selection function, typically an exponential function of linear predictors: (\exp(\mathbf{c}h(\mathbf{y}t, \mathbf{y}{t+1}) \cdot \boldsymbol{\beta}h^{(s_t)})).
- (\boldsymbol{\beta}h^{(st)}) are the state-dependent habitat selection coefficients.
- The denominator is a normalizing constant ensuring the function is a proper probability density [17].
Table 1: Key Components of the HMM-SSF Integrated Model
| Component | Description | Role in the Model |
|---|---|---|
| State Process ((S_t)) | A sequence of hidden behavioural states (e.g., "Encamped", "Exploratory"). | Governs the switching between behaviours according to a transition probability matrix. |
| Movement Kernel ((\phi)) | A probability density defining the distribution of step lengths and turning angles. | Models the movement mechanics and constraints for each behavioural state. |
| Selection Function ((w)) | A function weighting the relative selection for a location based on environmental covariates. | Quantifies how habitat features influence space use, conditional on behavioural state. |
| State-dependent Coefficients ((\boldsymbol{\beta}^{(s_t)})) | The parameters linking environmental covariates to selection strength in each state. | Allows habitat selection to vary between behaviours (e.g., strong selection in one state, neutral in another). |
Incorporating Mixed Effects
Biological data often possess hierarchical structures, such as repeated observations from the same individual or group. Linear Mixed Effects Models (LMMs) and their extensions are designed to handle such non-independent data by including both fixed effects (population-level averages) and random effects (group-specific deviations) [47].
In the context of HMMs, mixed effects can be incorporated into:
- The Transition Probabilities: Allowing the propensity to switch behaviours to vary among individuals.
- The State-dependent Parameters: Allowing baseline movement rates or habitat selection strengths to vary among individuals.
For example, the transition probability (\gamma_{ij}^{(k)}) for individual (k) to switch from state (i) to state (j) can be modelled on a logit scale as:
[ \text{logit}(\gamma{ij}^{(k)}) = \alpha{ij} + u_{ij}^{(k)} ]
where (\alpha{ij}) is the population-level fixed effect and (u{ij}^{(k)}) is an individual-specific random effect, typically assumed to be normally distributed around zero [47]. This accounts for individual "personality" or physiology affecting behavioural plasticity.
Application Notes & Experimental Protocols
Protocol: Fitting an HMM-SSF with Environmental Covariates
This protocol outlines the steps to implement the HMM-SSF model, using the analysis of plains zebra (Equus quagga) movement as an illustrative example [17].
Objective: To identify distinct behavioural states in zebra tracking data and quantify how habitat selection (for grassland) differs between these states.
Workflow Overview:
Step-by-Step Procedure:
Data Preparation and Covariate Extraction
- Input: A series of regular-time-interval animal locations ({\mathbf{y}1, \mathbf{y}2, \dots, \mathbf{y}_T}).
- Action: For each observed step (from (\mathbf{y}t) to (\mathbf{y}{t+1})), calculate:
- Movement Metrics: Step length and turning angle.
- Environmental Covariates: Extract values at the step's end point (\mathbf{y}_{t+1}). In the zebra example, this was the proportion of grassland at the endpoint [17].
- Output: A dataset where each row is an observed step, with associated movement and habitat variables.
Generate Availability Background Points
- Rationale: The SSF compares the used location to available, but unused, locations to infer selection [17].
- Action: For each observed step ending at (\mathbf{y}{t+1}), generate (K) random control steps that originate from the same starting point (\mathbf{y}t). These control steps should be drawn from a movement kernel (\phi) that reflects the animal's mobility constraints (e.g., based on the empirical distribution of step lengths and turning angles).
- Output: An expanded dataset containing both the observed ("used") step and (K) generated "available" steps for each original observation.
Specify Model Components
- State-dependent SSF: The likelihood for a used or available point (\mathbf{y}) is formulated as: [ p(\mathbf{y} \mid \mathbf{y}t, st) \propto \exp\left( \mathbf{c}h(\mathbf{y}t, \mathbf{y}) \cdot \boldsymbol{\beta}h^{(st)} + \mathbf{c}m(\mathbf{y}t, \mathbf{y}) \cdot \boldsymbol{\beta}m^{(st)} \right) ] where (\mathbf{c}h) are habitat covariates (e.g., grassland) and (\mathbf{c}m) are movement covariates (e.g., log(step length)) [17].
- Transition Probabilities: Specify a probability matrix (\Gamma) for switching between (N) states. This matrix can be constant or depend on covariates (e.g., time of day).
Parameter Estimation and State Decoding
- Estimation: Fit the HMM-SSF model by numerically maximizing the likelihood using the forward algorithm, which efficiently computes the likelihood of the observed data given the model parameters [46] [17].
- Decoding: Use the Viterbi algorithm to find the most likely sequence of hidden behavioural states across the entire track, and the forward-backward algorithm to calculate the probability of being in each state at each point in time [46].
Interpretation and Biological Inference
- State Classification: Interpret the identified states based on their movement parameters and habitat selection coefficients. In the zebra analysis, two states were identified:
- Encamped: Short steps, high turning angles.
- Exploratory: Long, directed steps [17].
- Habitat Selection: Examine the state-dependent habitat coefficients (\boldsymbol{\beta}h^{(st)}). The zebra analysis revealed selection for grassland in both states, but this selection was significantly stronger in the exploratory state [17].
- Space Use Estimation: The fitted model can be used in simulations to generate a behaviour-specific utilization distribution, providing a map of how the landscape is used differently across behaviours.
- State Classification: Interpret the identified states based on their movement parameters and habitat selection coefficients. In the zebra analysis, two states were identified:
Protocol: Adding Covariates to Transition Probabilities
Objective: To investigate how a temporal covariate (e.g., time of day) influences the probability of switching between behavioural states.
Workflow:
Define the Linear Predictor: For a transition from state (i) to state (j), model the transition probability as a function of a covariate (xt) (e.g., hour of the day, scaled). [ \eta{ij}^{(t)} = \log\left( \frac{\gamma{ij}^{(t)}}{1 - \gamma{ij}^{(t)}} \right) = \alpha{ij} + \beta{ij} xt ] Here, (\alpha{ij}) is an intercept and (\beta_{ij}) is the covariate effect on the log-odds of taking this transition [17].
Model Fitting and Interpretation: Include this linear predictor in the HMM likelihood computation. After fitting, a positive (\beta_{ij}) indicates that as the covariate increases, the animal becomes more likely to switch from state (i) to state (j). In the zebra example, a diel pattern was found, with a higher probability of transitioning to the "exploratory" state in the morning hours [17].
Table 2: Quantitative Results from a Hypothetical HMM-SSF Analysis of Zebra Movement
| Behavioural State | Step Length (km/h) | Turning Angle (rad) | Grassland Selection Coef. ((\beta)) | Diel Effect on Transition (Odds Ratio) |
|---|---|---|---|---|
| State 1: Encamped | 0.5 ± 0.1 | 1.2 ± 0.3 | 0.8 ± 0.2 | 0.6 (Lower in Day) |
| State 2: Exploratory | 3.2 ± 0.5 | 0.1 ± 0.1 | 2.1 ± 0.4 | 1.8 (Higher in Morning) |
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions for HMM Analyses
| Tool / Resource | Type | Function in Analysis |
|---|---|---|
| R Statistical Software | Software Platform | Primary environment for implementing and fitting HMMs and mixed models [47]. |
moveHMM / momentuHMM |
R Package | Provides functions to fit HMMs to animal tracking data, including covariate effects on transitions [17]. |
amt (Animal Movement Tools) |
R Package | Used for track manipulation, calculating step metrics, and generating availability points for SSFs [17]. |
| GPS Telemetry Collar | Hardware | Collects high-resolution spatiotemporal location data, the fundamental input for the analysis. |
| GIS Software (e.g., QGIS, ArcGIS) | Software Platform | Used to manage and process spatial data, including extraction of environmental covariate values to animal locations. |
| Random Forest Classifier | Algorithm | An alternative machine learning method sometimes used for comparative analysis or data pre-processing [48]. |
Critical Considerations
- Model Selection and Complexity: Adding covariates and random effects increases model complexity. Use information criteria (e.g., AIC) for model selection, but be aware of biases that can occur with mixed models [47].
- Computational Demand: Integrated HMM-SSF models and models with random effects are computationally intensive to fit, especially with large datasets. The forward algorithm is efficient, but the integration over the random effects distribution can be challenging [47] [17].
- Interpretation of States: The ecological meaning of hidden states must be inferred by the researcher by examining the state-dependent distributions and selection coefficients. They are not automatically labelled [46].
Overcoming Challenges: Scale Dependence, Model Selection, and Data Limitations
Hidden Markov Models (HMMs) have become a cornerstone technique for analyzing animal behavior from tracking data, enabling researchers to infer latent behavioral states from observed movement patterns [9] [32]. However, a critical methodological consideration—the sampling rate or temporal resolution of data collection—profoundly influences all aspects of state inference and parameter estimation [9]. This application note examines the scale dependence inherent in HMMs for animal movement, provides experimental protocols for determining appropriate sampling rates, and offers guidelines for robust experimental design to ensure reliable behavioral state classification.
The fundamental challenge stems from the discrete-time nature of most HMM formulations in movement ecology. Animal movement occurs in continuous time, but tracking devices sample this process at discrete intervals, creating a representation that is inherently tied to that specific temporal resolution [9]. As sampling frequency changes, so do the statistical properties of derived movement metrics, potentially altering the inferred behavioral states and transition dynamics.
Theoretical Foundations of Scale Dependence
HMM Framework for Animal Movement
In a typical HMM for animal movement, the observed process comprises step lengths and turning angles calculated from successive location fixes, while the hidden state process represents behavioral modes such as resting, foraging, or traveling [9]. The model consists of:
- State process: A first-order Markov chain with transition probability matrix Γ, where γᵢⱼ = Pr(Sₜ = j|Sₜ₋₁ = i) defines the probability of switching from state i to state j [9]
- Observation process: State-dependent distributions for step lengths (typically gamma distribution) and turning angles (typically von Mises distribution) [9]
- Initial state distribution: Probabilities of being in each state at the first observation
The conditional independence structure assumes that observations depend only on the current state, and states depend only on the immediately preceding state [9].
Mechanisms of Scale Dependence
The scale dependence in HMMs arises from two primary sources: the Markov chain governing state transitions and the correlated random walk describing movement within states [9]. For Markov chains, transition probabilities are defined for specific time intervals and do not scale linearly with time. For movement metrics, calculated step lengths and turning angles are heavily influenced by the time between observations, affecting the apparent tortuosity and speed of movement [9].
Table: Theoretical Effects of Increasing Sampling Interval on HMM Components
| HMM Component | Effect of Longer Intervals | Biological Interpretation Impact |
|---|---|---|
| Transition probabilities | Apparent state persistence increases | Animals appear to remain in states longer |
| Step length distribution | Mean and variance increase | Movement appears faster and more variable |
| Turning angle concentration | Apparent directional persistence decreases | Paths appear more tortuous |
| State classification | Boundaries between states may blur | Difficulty distinguishing similar behaviors |
This relationship can be visualized through the following conceptual framework:
Quantitative Evidence of Sampling Rate Effects
Empirical Findings from Animal Movement Studies
Research has demonstrated that sampling frequency significantly impacts derived movement parameters and state classification in animal tracking studies. In a simulation-based investigation of HMMs for animal movement, researchers found that all model parameters—including transition probabilities and movement parameters within each behavioral state—exhibited strong dependence on temporal resolution [9]. This scale dependence affects not only quantitative parameter estimates but also the qualitative classification of movement patterns into states, potentially leading to different biological interpretations of the same underlying behavior [9].
Parallel Evidence from Other Domains
Evidence from other fields using HMMs reinforces these concerns. In human activity recognition, reducing sampling frequency from 100 Hz to 10 Hz maintained recognition accuracy for most activities, but further reduction to 1 Hz significantly decreased accuracy for specific behaviors like brushing teeth [49]. Similarly, in non-intrusive load monitoring, appliance disaggregation accuracy using HMMs showed strong correlation with sampling rate for certain appliance types [50].
Table: Sampling Rate Effects Across Different HMM Application Domains
| Domain | Key Findings | Critical Sampling Threshold | Citation |
|---|---|---|---|
| Animal Movement | All HMM parameters show scale dependence; affects state classification | Highly species- and behavior-dependent | [9] |
| Human Activity Recognition | Accuracy maintained to 10 Hz; significantly decreased at 1 Hz | 10 Hz for clinical activity monitoring | [49] |
| Non-Intrusive Load Monitoring | Disaggregation accuracy correlated with sampling rate for specific appliances | Appliance-dependent | [50] |
| Brain State Identification | TDE-HMM outperforms Gaussian HMM for detecting phase-coupled states | Methodology-dependent | [51] |
Experimental Protocols for Sampling Rate Determination
Protocol 1: Sampling Rate Optimization for Novel Study Systems
Purpose: To determine the appropriate temporal sampling rate for HMM-based behavioral classification in a novel study system.
Materials:
- High-frequency tracking system (GPS, accelerometer, or video-based)
- Computational resources for HMM fitting and evaluation
- Data processing pipeline for resampling high-frequency data
Procedure:
- High-frequency data collection: Collect pilot data at the highest feasible temporal resolution (e.g., 1 Hz for GPS, 25 Hz for accelerometers) [49]
- Data resampling: Create multiple datasets by downsampling to various intervals (e.g., 1s, 5s, 15s, 30s, 60s, 120s, 300s)
- HMM fitting: Apply identical HMM structures to each resampled dataset
- Model assessment: Compare state classification consistency, parameter estimates, and biological interpretability across sampling rates
- Optimal rate selection: Identify the sampling rate that balances biological relevance, computational efficiency, and model stability
Expected Outcomes: A sampling rate recommendation specific to the study species and behaviors of interest, with documentation of how state classification changes across temporal resolutions.
Protocol 2: Validation of Behavioral State Classification
Purpose: To validate that HMM-inferred states correspond to biologically meaningful behaviors across different sampling rates.
Materials:
- Synchronized high-frequency tracking data and direct behavioral observations
- Annotation software for behavioral coding
- Statistical packages for classification validation
Procedure:
- Ground truth establishment: Collect direct behavioral observations (via video or live observation) synchronized with tracking data
- Multi-rate analysis: Apply Protocol 1 to generate state sequences at multiple sampling rates
- Cross-validation: Compare HMM-derived states with ground-truth behaviors using confusion matrices
- Accuracy quantification: Calculate classification accuracy, precision, and recall for each behavior at each sampling rate
- Rate optimization: Select the sampling rate that maximizes agreement with ground-truth behaviors while maintaining computational feasibility
Expected Outcomes: Quantified relationship between sampling rate and classification accuracy for specific behaviors, enabling evidence-based sampling rate selection.
The experimental workflow for determining optimal sampling rates integrates both computational and biological validation:
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Materials and Computational Tools for Sampling Rate Studies
| Item | Function | Specification Considerations |
|---|---|---|
| High-frequency GPS tags | Primary data collection for movement studies | Battery life trade-offs with sampling frequency; accuracy of ~1-5m |
| Tri-axial accelerometers | Fine-scale movement data for behavior classification | Sampling rate typically 10-100Hz; memory capacity for long deployments |
| Video tracking systems | Ground truth validation for behavior states | Synchronization with electronic tags; manual or automated annotation |
| HMM software packages | Model fitting and state decoding | moveHMM, MomentuHMM, or custom implementations in R/Python |
| Data resampling tools | Creating multiple temporal resolutions | Custom scripts for systematic downsampling of high-frequency data |
| Validation datasets | Benchmarking sampling rate effects | Publicly available tracking data with known behaviors |
Implementation Guidelines and Recommendations
Practical Recommendations for Researchers
Based on the documented scale dependence of HMMs, researchers should adopt the following practices:
- Pilot studies: Conduct small-scale pilot studies at high temporal resolution to inform sampling rate selection for full deployments [49]
- Consistent sampling: Maintain consistent sampling rates within and across studies to enable valid comparisons [9]
- Metadata documentation: Thoroughly document sampling protocols to enable proper interpretation of results [9]
- Multi-scale analysis: Explore sensitivity of results to sampling rate when possible, especially in novel study systems [9]
- Biological validation: Ground-truth HMM classifications with direct behavioral observations across sampling rates [32]
Reporting Standards for Methodological Transparency
To enhance reproducibility and facilitate meta-analyses, publications using HMMs for behavioral classification should include:
- Exact sampling rate and device specifications
- Justification for sampling rate selection
- Assessment of potential scale dependence on conclusions
- Software and package versions used for analysis
- Complete HMM specification including distributions and constraints
The sampling rate dilemma represents a fundamental challenge in HMM-based analysis of animal behavior. Temporal resolution affects all aspects of state inference, from parameter estimation to behavioral classification [9]. By understanding these scale dependencies and implementing rigorous protocols for sampling rate selection and validation, researchers can enhance the reliability and biological relevance of their behavioral classifications. The protocols and guidelines presented here provide a pathway toward more robust and reproducible inference of animal behavior from tracking data.
A fundamental challenge in using Hidden Markov Models (HMMs) for classifying animal behavior from tracking data is selecting the optimal number of behavioral states. An underestimated number of states may oversimplify behavioral complexity, while an overestimated one may lead to overfitting and biologically meaningless separation [52]. This Application Note provides a structured framework for this model selection process, focusing on information-theoretic criteria and validation protocols essential for robust inference in movement ecology.
The core of an HMM consists of a latent state process and an observation process. The model is defined by:
- Transition probabilities ( governing state switching)
- Emission probabilities ( linking states to observed data) [1]
When applied to animal tracking, the latent states typically represent behavioral modes (e.g., foraging, traveling, resting), while observations are movement metrics such as step lengths and turning angles derived from location data [15] [17].
Theoretical Foundation: Model Selection Criteria
Information Criteria for Model Selection
The two primary criteria for selecting the number of states in an HMM are the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). Both balance model fit against complexity but have different theoretical underpinnings and performance characteristics [53].
Table 1: Comparison of Key Model Selection Criteria
| Criterion | Formula | Penalty Term | Appropriate Use Case |
|---|---|---|---|
| Akaike Information Criterion (AIC) | -2 log(L) + 2K | 2K | Predictive accuracy; smaller datasets/complex realities |
| Bayesian Information Criterion (BIC) | -2 log(L) + K log(T) | K log(T) | Identifying true model; larger datasets |
Where:
- L = maximized value of the model likelihood
- K = total number of estimated parameters
- T = sample size (number of observations)
The model with the lowest AIC or BIC value is considered optimal. The BIC's penalty term, which includes sample size, typically favors simpler models more strongly than AIC as dataset size increases [53].
Limitations of Likelihood-Based Selection
It is crucial to note that the model log-likelihood (LL) alone is unsuitable for model selection, as it invariably increases with additional parameters, creating overfitting risk [53]. Information criteria provide the necessary penalization for complexity that raw likelihood lacks.
Experimental Protocols for Model Selection
Core Workflow for State Number Determination
The following workflow outlines the standard procedure for determining the optimal number of behavioral states.
Detailed Protocol Steps
Step 1: Data Preparation and Movement Metric Calculation
- Obtain tracking data: Collect regularly-spaced location data (e.g., from GPS tags) with negligible measurement error [15].
- Calculate step lengths: Compute Euclidean distances between consecutive locations. These are non-negative, continuous values often modeled using Gamma distributions [4] [17].
- Calculate turning angles: Compute direction changes between consecutive steps. These are circular-valued (radians, support: -π, π) often modeled using von Mises or wrapped Cauchy distributions [4].
Step 2: Model Fitting with Multiple Initializations
- Specify state range: Define a plausible range of states to evaluate (e.g., from 2 to 5) based on biological knowledge [52].
- Address local maxima: For each candidate state number (e.g., n=2,3,4,5), fit multiple HMMs (e.g., 10 iterations) with different random starting values for parameters [53].
- Retain best model: For each state number, select the model with the highest log-likelihood from the multiple runs for subsequent criterion calculation [53].
Step 3: Calculation of Selection Criteria
- Extract log-likelihood: Obtain the maximized log-likelihood (LL) value from the best model for each state number.
- Count parameters: Calculate total parameters (K) for each model. For an HMM with N states, this includes:
- Transition probabilities: N(N-1) parameters
- Emission parameters: e.g., N × (number of parameters per state-dependent distribution) [1]
- Compute AIC/BIC: Apply formulas from Table 1 for each candidate model.
Step 4: Validation and Interpretation
- Identify optimal model: Select the state number corresponding to the minimum AIC/BIC value [53].
- Check biological plausibility: Examine the decoded behavioral time series and state-dependent distributions to ensure ecological meaningfulness [19].
- Consider simulation: If uncertainty remains, implement a simulation study to verify the selected model's ability to recover known states [15].
Practical Application and Case Studies
Implementation Example: Gaussian HMM
A practical example from the hmmlearn Python package demonstrates the selection process for a Gaussian HMM analyzing simulated data with known properties [53]:
Table 2: Research Reagent Solutions for HMM Implementation
| Tool/Resource | Type | Primary Function | Application Context |
|---|---|---|---|
| hmmlearn (Python) | Software Library | HMM fitting with AIC/BIC methods | General purpose HMM implementation [53] |
| moveHMM (R) | R Package | HMM for animal movement tracks | Step length & turning angle analysis [15] |
| TMB (R) | R Package | HMM fitting via maximum likelihood | Rapid estimation for complex models [15] |
| Animal Tag Tools | MATLAB Toolbox | Sensor data preprocessing | IMU data calibration & transformation [19] |
Code Implementation Outline:
Case Study: Albatross Foraging Behavior
In a study of four albatross species, researchers used HMMs to classify three behavioral states from high-resolution accelerometer and magnetometer data [19]:
- Behavioral States: 'flapping flight', 'soaring flight', and 'on-water'
- Model Performance: Overall classification accuracy of 92%
- State-specific Accuracy:
- Flapping flight: 87.6%
- Soaring flight: 93.1%
- On-water: 91.7%
This study demonstrated that HMMs provide a flexible and interpretable framework for behavioral classification, though the addition of magnetometer data to accelerometer data did not significantly improve classification accuracy for these broad behavioral categories [19].
Advanced Considerations and Methodological Extensions
Integrated HMM-SSF Framework
A recent advancement integrates HMMs with Step Selection Functions (SSFs) to jointly model behavioral state switching and habitat selection [17]. This HMM-SSF framework:
- Simultaneously estimates behavioral states and habitat selection parameters
- Reduces bias by avoiding a two-stage approach that first classifies states then fits habitat models
- Allows covariates to influence transition probabilities between states (e.g., diel cycles) [17]
In a zebra case study, this approach identified two distinct behavioral states ("encamped" and "exploratory") with clearly different habitat selection patterns, and revealed a diel cycle in behavior with higher probability of exploration in morning hours [17].
Accounting for High-Resolution Data
For high-resolution tracking data (e.g., ≥1Hz), standard HMMs may violate the conditional independence assumption due to momentum in animal movement. Autoregressive HMMs address this by incorporating lagged observations into the state-dependent distributions [4]:
- Autoregressive components can be added to both step length and turning angle processes
- Model formulation for step length mean with autoregressive component: μ{t,j} = Σ{k=1}^{p} φ{j,k} x{t-k} + (1 - Σ{k=1}^{p} φ{j,k}) μ_j
- Order selection for autoregressive terms can be automated using lasso regularization [4]
Addressing the Optimal State Number Dilemma
Despite formal criteria, selecting states remains challenging:
- Financial markets analogy: One study rejected the hypothesis that two regimes (bull/bear markets) suffice, finding between 2-5 states needed for different assets [52].
- Biological interpretation: The optimal statistical model must produce biologically meaningful states [19] [17].
- Practical consideration: More states create complex interpretation challenges even if statistically superior [52].
Determining the optimal number of behavioral states in HMMs requires a systematic approach combining information-theoretic criteria (AIC/BIC) with biological validation. The protocols outlined here provide a framework for robust model selection applicable across diverse species and tracking systems. As methodological developments continue, particularly in integrated HMM-SSF frameworks and autoregressive structures for high-resolution data, researchers gain increasingly powerful tools for uncovering the behavioral complexity underlying animal movement patterns.
Handling Data Gaps and Irregular Sampling Intervals in Longitudinal Studies
Longitudinal studies, which involve repeated observations of the same variables over time, are fundamental to understanding animal behavior from tracking data. However, these studies inherently suffer from two major methodological challenges: missing data and irregular sampling intervals. In studies of older animals or long-term tracking, the susceptibility to health decline, device failure, and environmental factors creates significant data gaps, with missing data ranging from 0.1% to 55% and averaging approximately 14% in gerontological studies [54]. Similarly, traditional regular sampling intervals often fail to capture important behavioral transitions, leading to incomplete behavioral classification. Within the context of hidden Markov models (HMMs) for classifying animal behavior, these data challenges can substantially impact parameter estimation and state decoding accuracy if not properly addressed. This application note provides structured protocols and solutions for handling these issues within the framework of movement ecology research.
Understanding Missing Data Mechanisms and Patterns
Classification of Missing Data Mechanisms
Proper handling of missing data requires understanding their underlying mechanisms, which determine the appropriate analytical approach. Rubin (1976) established a fundamental taxonomy distinguishing three missing data mechanisms [55]:
Table 1: Classification of Missing Data Mechanisms in Longitudinal Studies
| Mechanism | Acronym | Definition | Ignorability |
|---|---|---|---|
| Missing Completely at Random | MCAR | Missingness is unrelated to both observed and unobserved data | Ignorable |
| Missing at Random | MAR | Missingness can be explained by observed data only | Ignorable |
| Missing Not at Random | MNAR | Missingness depends on unobserved data | Non-ignorable |
In practice, multiple mechanisms may operate simultaneously within a single dataset. For animal tracking studies, MCAR might occur due to random device malfunction, MAR when missingness relates to previously observed environmental conditions, and MNAR when animals in specific behavioral states (e.g., deep diving) are less likely to be detected.
Current Reporting and Handling Practices
The reporting and handling of missing data in longitudinal biological studies remains inadequate. A methodological survey of geriatric journals found that in approximately 62.5% of studies, there was either no comment on missing data or descriptions were unclear [54]. Complete case analysis was the most common method for handling missing data, used in nearly 75% of studies, despite its potential for bias unless data are truly MCAR. Only 10% of studies using multiple imputation fully reported the procedure. These deficiencies highlight the need for standardized reporting and analytical protocols in movement ecology studies.
Protocol for Handling Missing Data in Animal Tracking Studies
Assessment and Documentation of Missing Data
Objective: Systematically quantify and characterize missing data patterns in animal tracking datasets prior to HMM implementation.
Procedure:
- Calculate missing data percentage: For each animal and tracking variable (location, depth, speed, etc.), compute the percentage of missing observations relative to total expected observations.
- Document missing data patterns: Create a missing data matrix visualizing missingness across individuals and time points.
- Explore mechanisms: Conduct exploratory analyses comparing animals with complete versus incomplete data on observed covariates (e.g., sex, age, environmental conditions).
- Report comprehensively: Document the amount of missing data, suspected mechanisms, and methods used for handling missingness in all publications.
Expected Outcomes: Transparent reporting enables readers to assess potential biases and appropriateness of analytical methods. Documentation should include flow charts illustrating participant attrition similar to those used in clinical studies [56].
Analytical Methods for Handling Missing Data
Complete Case Analysis:
- Description: Analysis restricted to individuals with complete data across all time points.
- Implementation: Simple to implement but generally not recommended unless missingness is minimal (<5%) and MCAR.
- Limitations: Inefficient (discards available data) and prone to selection bias if data are not MCAR.
Multiple Imputation:
- Description: Generates multiple complete datasets by replacing missing values with plausible values based on observed data.
- Implementation:
- Specify imputation model including all analysis variables and auxiliary variables related to missingness.
- Generate 20-100 imputed datasets depending on percentage of missing data.
- Analyze each complete dataset using standard HMM approaches.
- Combine parameter estimates using Rubin's rules.
- Advantages: Valid under MAR mechanism, utilizes all available information.
- Reporting Requirements: Specify variables used, number of imputations, software implementation, and evaluation of convergence [54].
Maximum Likelihood Methods:
- Description: Direct estimation of parameters from available data using likelihood-based approaches.
- Implementation: Utilizes all available data under MAR assumption without imputing missing values.
- Advantages: Statistically efficient and avoids imputation uncertainty.
- HMM Context: The hidden Markov movement model (HMMM) uses maximum likelihood estimation via the R package TMB for rapid model fitting [15].
Table 2: Comparison of Missing Data Handling Methods for HMM Applications
| Method | Mechanism Assumption | Implementation Complexity | Suitability for HMM | Software Options |
|---|---|---|---|---|
| Complete Case | MCAR | Low | Poor | Standard HMM packages |
| Multiple Imputation | MAR | Medium | Good (after imputation) | mice, Amelia + moveHMM |
| Maximum Likelihood | MAR | Medium-High | Excellent | swim, TMB [15] |
| Bayesian Approaches | MAR/MNAR | High | Excellent | Stan, JAGS |
Protocol for Handling Irregular Sampling Intervals
LARI Sampling Design for Movement Studies
Background: Traditional regular sampling intervals may miss important behavioral transitions, particularly for animals exhibiting both regular and sporadic behaviors. The Lattice and Random Intermediate Point (LARI) sampling regime addresses this limitation by combining regular and irregular sampling [57].
Procedure:
- Establish a baseline regular sampling interval (e.g., every 24 hours) based on biological knowledge and resource constraints.
- Between each regular interval, collect one additional observation at a random time point.
- Ensure the total number of observations remains constant for fair comparison with regular sampling designs.
- Implement in field studies by programming tracking devices with this hybrid schedule.
Validation: Application to three study systems (ants, guppies, and simulated data) demonstrated that LARI sampling provided better understanding of animal behavior and more accurate estimates of movement parameters than regular sampling with the same number of data points [57].
HMM Adaptation for Irregular Intervals
Objective: Modify HMM framework to accommodate irregular time intervals between observations.
Theoretical Framework: The hidden Markov movement model (HMMM) implements the process equation of the first-Difference Correlated Random Walk with Switching (DCRWS) within a maximum likelihood framework [15]. For irregular intervals, the model can be extended by incorporating time-dependent transition probabilities.
Implementation:
- Preprocessing: Calculate exact time differences between consecutive observations.
- Model Specification: Define the HMM with continuous-time transition probabilities or discrete-time approximations with time-dependent covariates.
- Parameter Estimation: Utilize the R package
swimwhich implements the HMMM with capacity for irregular observations [15]. - Validation: Conduct simulation studies to verify model performance under known irregular sampling schemes.
Diagram 1: Workflow for Handling Data Gaps and Irregular Intervals in HMM Analysis
Integrated Analytical Framework for HMM with Imperfect Data
Comprehensive Workflow Protocol
Objective: Provide an integrated analytical pipeline addressing both missing data and irregular sampling intervals for behavioral classification using HMMs.
Procedure:
- Data Quality Assessment:
- Quantify percentage of missing data for each individual and variable.
- Visualize missing data patterns using heat maps or specialized missing data plots.
- Document sampling intervals and identify irregular patterns.
Mechanism Evaluation:
- Conduct exploratory analysis to identify predictors of missingness.
- Make preliminary determination of missing data mechanism (MCAR, MAR, MNAR).
Method Selection and Implementation:
- For data with minimal missingness (<5%) suspected to be MCAR: use complete case analysis.
- For data with substantial missingness suspected to be MAR: implement multiple imputation or direct maximum likelihood.
- For irregular sampling intervals: implement LARI sampling design where possible and use HMMM framework for analysis.
Model Fitting:
- Fit hidden Markov movement model using
swimR package [15]. - Specify appropriate movement characteristics (turning angles, step lengths) corresponding to behavioral states.
- Incorporate environmental covariates that may influence both movement and missingness.
- Fit hidden Markov movement model using
Sensitivity Analysis:
- Compare results across different missing data handling methods.
- Test robustness to assumptions about missing data mechanisms.
- Vary HMM specifications (number of states, covariate inclusion).
Validation:
- Use simulated data with known parameters to validate approach.
- Compare classified behaviors with direct observations where available.
- Assess biological plausibility of results.
Diagram 2: HMM Structure for Animal Behavior Classification with Imperfect Data
Table 3: Essential Computational Tools for Handling Data Gaps in Movement Ecology
| Tool/Resource | Type | Primary Function | Application Context |
|---|---|---|---|
R Package swim |
Software | Implements hidden Markov movement model (HMMM) | Fitting HMMs to animal tracking data with negligible error [15] |
R Package TMB |
Software | Maximum likelihood estimation for random effects models | Efficient model fitting for complex HMM specifications [15] |
R Package moveHMM |
Software | Hidden Markov models for animal movement data | Standard HMM implementation for regular sampling intervals |
R Package mice |
Software | Multiple imputation of missing data | Handling missing values under MAR mechanism |
| LARI Sampling | Methodology | Combined regular and random sampling design | Optimizing sampling regime for behavioral classification [57] |
| Bayesian State-Space Models | Methodology | Integrated modeling of measurement error and behavior | Handling both measurement error and missing data |
| Color Contrast Analyzers | Accessibility Tool | Ensure sufficient visual contrast in diagrams | Creating accessible data visualizations [58] [59] |
Effectively handling data gaps and irregular sampling intervals is essential for valid inference when using hidden Markov models to classify animal behavior from tracking data. The protocols outlined in this application note provide a comprehensive framework for addressing these challenges, from initial data assessment through final model validation. By implementing structured approaches for missing data handling, such as multiple imputation or direct maximum likelihood estimation, and adopting optimized sampling designs like LARI, researchers can significantly improve the accuracy and biological relevance of their behavioral classifications. The integrated workflow combines these elements within the HMMM framework, enabling researchers to extract robust behavioral insights from imperfect field data while maintaining methodological rigor and transparency.
In the analysis of animal movement data, Hidden Markov Models (HMMs) have become a cornerstone technique for identifying underlying behavioral states from observed tracking data [15]. These models are powerful statistical tools that assume an animal's movement is driven by a finite set of hidden behavioral states that evolve according to a Markov process [60]. The fundamental challenge facing researchers is navigating the trade-off between model complexity, which can capture finer behavioral nuances, and interpretability, which ensures biological relevance and practical utility [4]. As movement datasets grow in resolution and dimensionality, with modern sensors collecting data at frequencies up to 30 Hz [32], this balancing act becomes increasingly critical. This article examines the computational considerations in HMM implementation for animal behavior classification, providing structured guidance and protocols for researchers working with tracking data.
Core Concepts of Hidden Markov Models in Animal Movement
HMMs are doubly stochastic models consisting of an unobserved state process and observed emissions [60]. In movement ecology, the hidden states typically represent behavioral modes such as resting, foraging, or traveling, while the observations are movement metrics derived from tracking data.
The mathematical foundation of HMMs comprises three core elements [60]:
- Transition probabilities (A): The matrix governing probabilities of switching between states, defined as γᵢⱼ = Pr(Sₜ = j | Sₜ₋₁ = i)
- Emission probabilities (B): The distributions of observations conditional on the hidden state, typically step lengths and turning angles
- Initial state distribution (δ): The probabilities of starting in each state
For animal movement applications, the process equation is often formulated as: dₜ = γbₜ₋₁T(θbₜ₋₁)dₜ₋₁ + N₂(0,Σ) where dₜ represents the differences between consecutive locations, γ is the autocorrelation parameter, T is the rotational matrix for turning angles, and Σ is the covariance matrix [15].
Computational Trade-offs: Model Complexity Versus Interpretability
The Complexity Spectrum in HMMs
The table below outlines the primary dimensions of model complexity in HMMs for animal behavior classification:
Table 1: Dimensions of Model Complexity in Animal Behavior HMMs
| Complexity Dimension | Simple Model | Complex Model | Computational Impact |
|---|---|---|---|
| Number of States | 2-3 behavioral states | 4+ behavioral states | Increased parameter space; risk of overfitting |
| Emission Distributions | Basic distributions (gamma, von Mises) | Multivariate distributions with covariates | Heavier computation per iteration |
| Dependence Structure | Conditional independence given state | Autoregressive components (AR-HMM) | More complex likelihood evaluation |
| Covariate Integration | No covariates | State transition covariates | Increased model fitting time |
| Measurement Error | Negligible error assumption | Integrated error modeling | Additional latent variables |
Consequences of Model Over-simplification
- Failure to Capture Behavioral Nuances: Basic HMMs assume conditional independence of observations given the state process, which becomes problematic with high-resolution data where physical momentum creates serial correlation [4].
- State Misclassification: In homogeneous environments where animals "forage on the go," simple models struggle to distinguish foraging from traveling behaviors, leading to misclassification [18].
- Inadequate Representation of Periodicity: Models that ignore diel patterns fail to capture biologically meaningful behavioral shifts tied to daily cycles [61].
Consequences of Excessive Complexity
- Overfitting: Increasing model complexity expands the parameter space, requiring more data for reliable estimation [60].
- Computational Burden: Complex models with autoregressive components and multiple random effects require more sophisticated estimation techniques and computation time [15] [4].
- Interpretation Challenges: As the number of states increases, providing biologically meaningful labels for each state becomes increasingly difficult [18].
Practical Implementation Protocols
Protocol 1: Model Selection Framework for Behavioral Classification
Objective: Systematically select an HMM structure that balances complexity and interpretability for animal movement data.
Materials and Software:
- Tracking data (GPS, acoustic telemetry, or high-resolution sensor data)
- R statistical environment with packages:
momentuHMM,moveHMM, orswim[15] [36] - Computational resources appropriate for data size and model complexity
Procedure:
Data Preparation and Exploration
- Calculate step lengths and turning angles from raw location data
- Visually explore distributions of movement metrics to inform initial state definitions
- For high-resolution data (>1 Hz), consider downsampling to reduce autocorrelation [32]
Initial Model Fitting
- Begin with a basic 2-state HMM using gamma distributions for step lengths and von Mises distributions for turning angles
- Define initial parameter values informed by ecological knowledge
- Fit model using maximum likelihood estimation [15]
Model Diagnostics and Validation
Iterative Complexity Addition
- If model fit is inadequate, incrementally add complexity: a. Incorporate autoregressive components for step lengths and turning angles [4] b. Add state transition covariates (e.g., time of day, environmental variables) c. Increase number of states if biologically justified
- At each step, verify that likelihood improvements justify complexity increases
Final Model Selection
- Use information criteria (AIC, BIC) for formal model comparison
- Prioritize models with clearest biological interpretation
- Document all candidate models and selection rationale
Protocol 2: Handling High-Resolution Movement Data
Objective: Address unique challenges of high-resolution tracking data (>1 Hz) while maintaining model interpretability.
Background: High-frequency data introduces substantial autocorrelation that violates the conditional independence assumption of basic HMMs [4].
Procedure:
Data Preprocessing
- Implement ethical downsampling strategies to reduce autocorrelation while preserving behavioral signals [32]
- Consider calculating movement metrics over varying time windows to capture different behavioral scales
Autoregressive HMM Implementation
- Specify autoregressive order (p) for step lengths and turning angles within states: μₜ,ⱼᵗᵉᵖ = ∑ₖ₌₁ᵖⱼᵗᵉᵖ φⱼ,ₖᵗᵉᵖ xₜ₋ₖᵗᵉᵖ + (1 - ∑ₖ₌₁ᵖⱼᵗᵉᵖ φⱼ,ₖᵗᵉᵖ) μⱼᵗᵉᵖ [4]
- Use lasso regularization to automatically select autoregressive order [4]
- Model step length standard deviation with constant coefficient of variation: σₜ,ⱼᵗᵉᵖ = ωⱼ μₜ,ⱼᵗᵉᵖ [4]
Computational Optimization
- Utilize Template Model Builder (TMB) for rapid maximum likelihood estimation [15]
- Implement parallel processing for bootstrap validation
- Consider Bayesian estimation methods (MCMC) for complex random effects structures
Table 2: Research Reagent Solutions for Animal Behavior HMMs
| Tool/Category | Specific Examples | Function/Purpose |
|---|---|---|
| R Packages | momentuHMM, moveHMM, swim |
Implement HMMs for animal movement data with various complexity levels [15] [36] |
| Data Processing | trackR, amt, move |
Preprocess tracking data, calculate step lengths and turning angles |
| Model Diagnostics | viterbi, pseudoResiduals |
Decode state sequences and assess model fit [60] |
| Auxiliary Validation | Accelerometers, wet-dry sensors, time-depth recorders | Provide independent behavioral validation for HMM classifications [18] |
| High-Resolution Analysis | Autoregressive HMM extensions | Model within-state serial correlation in high-frequency data [4] |
| Visualization | ggplot2, plotHMM |
Visualize tracks, state distributions, and model results |
Workflow Visualization
HMM Implementation Workflow for Animal Behavior Classification
Case Studies in Complexity Management
Case Study 1: Seabird Foraging in Homogeneous Environments
Challenge: Red-billed tropicbirds foraging in tropical waters exhibit "looping trips" with sporadic, short-lived foraging events difficult to distinguish from traveling using basic HMMs [18].
Solution Approach:
- Initial 3-state HMM (resting, foraging, traveling) showed poor foraging classification accuracy (sensitivity: 0.37 ± 0.06)
- Incorporated wet-dry sensor data and dive records as semi-supervised training
- Implemented constrained state transitions reflecting biological knowledge
Result: Model accuracy improved from 0.77 ± 0.01 to 0.85 ± 0.01 despite using only 9% of informed data points [18].
Case Study 2: High-Resolution Tern Foraging Analysis
Challenge: Basic HMMs failed to capture short-lived foraging maneuvers in 30 Hz tern tracking data due to strong within-state autocorrelation [4].
Solution Approach:
- Implemented autoregressive HMM with lag-p components for both step lengths and turning angles
- Used lasso regularization for automatic order selection
- Modeled step lengths with gamma distribution featuring constant coefficient of variation
Result: Improved identification of foraging attempts represented as troughs in step length time series [4].
The effective application of HMMs for animal behavior classification requires careful navigation of the complexity-interpretability trade-off. Through structured model selection, appropriate computational tools, and biological validation, researchers can develop models that are both statistically adequate and ecologically meaningful. The protocols and case studies presented here provide a framework for implementing HMMs that balance these competing demands while accommodating the specific challenges of modern animal tracking data. As sensor technologies continue to evolve, maintaining this balance will remain essential for extracting biologically meaningful insights from movement data.
Hidden Markov Models (HMMs) have emerged as a powerful tool for classifying animal behavior from tracking data, revealing behavioral states such as "Resting," "Exploring," and "Navigating" that are not directly observable [10] [3]. However, a significant challenge lies in validating that these computationally inferred states represent genuine, biologically plausible behaviors rather than statistical artifacts. Without rigorous validation, inferences about state-dependent habitat selection or treatment effects may be misleading [17]. This application note details a comprehensive framework to ensure the biological plausibility of HMM-inferred behavioral states, providing essential protocols for researchers and scientists applying these methods in preclinical and drug development research.
The need for such a framework is underscored by the limitations of traditional behavioral metrics. Simple measures like time spent in different zones show high variability and are often confounded by non-visual behaviors such as general exploration or anxiety [10]. The framework adapts and extends the "V3" validation principles—Verification, Analytical Validation, and Clinical/Biological Validation—for the specific context of behavioral HMMs, ensuring that digital measures accurately reflect underlying biological phenomena [62].
Core Validation Framework: The Adapted V3 Principles for Behavioral HMMs
A robust validation strategy for behavioral HMMs should be implemented across three sequential stages, adapted from the clinical digital measures framework [62]. The table below summarizes the key questions and objectives for each stage.
Table 1: The Three-Stage Validation Framework for Behavioral HMMs
| Validation Stage | Core Question | Primary Objective | Key Methods |
|---|---|---|---|
| 1. Verification | Does the HMM accurately capture and process the raw tracking data? | Ensure integrity of input data and technical execution of the HMM. | Sensor calibration, data preprocessing checks, model convergence diagnostics. |
| 2. Analytical Validation | Do the inferred states correspond to specific, distinguishable behavioral motifs? | Assess the algorithm's accuracy in segmenting behavior based on movement metrics. | Examination of emission parameters, sequence decoding analysis, goodness-of-fit tests. |
| 3. Biological Validation | Do the computationally inferred states represent meaningful biological behaviors? | Establish that states reflect ecologically or biologically relevant conditions or responses. | Positive control experiments, pharmacological interventions, cross-method correlation with manual scoring. |
Stage 1: Verification of Data and Model Integrity
Verification ensures the raw data and model implementation are sound. This involves:
- Sensor and Tracking Verification: Confirm that the tracking technology (e.g., video cameras, DeepLabCut) accurately captures animal position and movement. This includes verifying spatial and temporal resolution and ensuring consistent lighting to prevent artifacts [3] [62].
- Data Preprocessing Pipeline: Implement and document steps for handling raw coordinates, such as smoothing and calculating derived movement metrics (e.g., step length and turning angle). The pipeline must be consistent and reproducible [3] [17].
- HMM Implementation and Convergence: Use established libraries (e.g., Stan) and demonstrate that model parameters converge reliably during estimation, with no dependence on arbitrary initial values [10].
Stage 2: Analytical Validation of State Distinction
Analytical validation assesses whether the HMM cleanly segments the behavioral stream into distinct states.
- Eission Distribution Analysis: Examine the distributions of observed variables (e.g., step length, turning angle) associated with each state. Biologically plausible states should have emission distributions that are distinct and interpretable (e.g., a "Resting" state with very short step lengths and high turning angle variance) [17].
- State Sequence Decoding: Analyze the sequence of decoded states (e.g., using the Viterbi algorithm) [63]. The model should infer reasonably persistent states, not rapid, erratic switching that is biologically implausible for the species and timescale.
- Goodness-of-Fit: Check the model's ability to reproduce key features of the observed data, such as the distribution of bout durations or overall activity budgets.
Stage 3: Biological Validation of State Meaning
This is the most critical stage for establishing biological plausibility, moving from statistical patterns to biological meaning.
- Face Validity via Positive Controls: Conduct experiments where a specific behavioral response is expected. For example, in a visual cliff test, wild-type mice with functional depth perception should show increased "Resting" or avoidance behavior near the cliff edge, while visually impaired models (e.g., rd1-2J mice) should not [10] [3]. This demonstrates that the state dynamics are driven by the intended sensory input.
- Pharmacological Challenges: Administer compounds with known behavioral effects (e.g., stimulants or sedatives). A biologically plausible "Resting" state should be significantly increased by a sedative and decreased by a stimulant.
- Convergent Validity: Compare HMM-inferred states with independent behavioral assessments, such as manual scoring by trained ethologists or measurements from other bio-sensors (e.g., electromyography for muscle activity). High correlation between methods strengthens the biological interpretation of the states [62].
Diagram 1: A sequential workflow for the three-stage validation of HMM-inferred behavioral states.
Application Protocol: Validating Depth Perception in a Mouse Visual Cliff Assay
This protocol details a specific application of the validation framework to a visual cliff test, a paradigm used to assess depth perception and its recovery in mouse models of retinal degeneration and treatment [10] [3].
Experimental Setup and Reagents
Table 2: Essential Research Reagents and Solutions for the Visual Cliff Assay
| Item | Specification/Function | Rationale |
|---|---|---|
| Circular Visual Cliff Apparatus | 60 cm inner diameter, no corners [10] [3]. | Eliminates corner-preference confounds, promoting natural exploration near the cliff edge. |
| High-Contrast Checkerboard | 2 cm squares, 1:0 black-white contrast ratio [3]. | Provides unambiguous visual depth cues for the mouse. |
| Overhead Lighting | 3000 K, 50% intensity, 65 cd/m² [3]. | Balances animal comfort with sufficient illumination for consistent video tracking. |
| Video Tracking System | DeepLabCut for markerless pose estimation [10] [3]. | Provides high-precision, non-invasive tracking of body center and other key points. |
| Animal Models | Wild-type (C57BL/6J) and retinal degeneration (rd1-2J) mice [10] [3]. | Serves as positive and negative controls for visual function, respectively. |
Step-by-Step HMM Analysis and Validation Procedure
Data Acquisition:
- Place a single mouse on the central platform of the circular visual cliff apparatus, facing the shallow side.
- Record a 10-minute trial from directly above. Use only the first 3 minutes for analysis to capture the initial, unhabituated response [3].
- Export video for analysis with DeepLabCut to obtain the x, y coordinates of the body center at a 10 Hz sampling rate [10].
Movement Metric Calculation:
- From the body center coordinates, calculate the step length (lₜ) as the Euclidean distance between consecutive frames [3]: lₜ = √[(xₜ - xₜ₋₁)² + (yₜ - yₜ₋₁)²]
- Calculate the turning angle as the change in direction between consecutive movement steps.
HMM Implementation:
- Implement a 3-state HMM using a probabilistic programming language like Stan [10]. The observation model for each state is defined by distributions of step lengths and turning angles.
- Fit the model to the sequence of derived movement metrics. Assume the states correspond to "Resting," "Exploring," and "Navigating" [10].
Validation Execution:
- Analytical Validation: Plot the distributions of step length and turning angle for each inferred state. The "Resting" state should be characterized by very short steps and high directional variance, while "Navigating" should show longer, more directed steps [10] [17].
- Biological Validation with Positive Controls:
- Compare the state probabilities of wild-type (WT) and retinal degeneration (RD) mice in the deep-side zone of the apparatus.
- A validated model will show that WT mice have a significantly higher probability of being in the "Resting" state and a lower probability of "Navigating" on the deep side compared to the RD mice, which should behave randomly with respect to the cliff [3].
- Biological Validation with Habituation:
- Conduct repeated trials and analyze the state dynamics over time. A biologically plausible model will capture the phenomenon of "state collapse," where the distinct "Exploring" state diminishes as the animal learns the cliff is not a real threat and behavior simplifies to alternation between "Resting" and "Navigating" [3].
Interpreting Results and Recognizing Pitfalls
Successful validation is indicated by several key outcomes. The HMM should infer stable, persistent behavioral bouts, and the emission parameters should align with ethological expectations. Crucially, the model must detect predictable differences between positive and negative control groups (e.g., WT vs. RD mice) and show dynamic, interpretable changes in state structure over time or in response to interventions [3].
Common pitfalls include:
- Misinterpretation of States: A state might reflect an experimental artifact (e.g., thigmotaxis, or wall-hugging) rather than a volitional behavior. Correlation with manual scoring is essential.
- Over-reliance on a Single Metric: Do not validate a "Resting" state on step length alone; also check for correspondence with postural data (e.g., a hunched body shape from DeepLabCut).
- Ignoring Context: A state's biological meaning is context-dependent. "Resting" could indicate sleep, vigilance, or sickness behavior; the experimental context and additional measures are needed for a definitive interpretation.
Integrating the V3 validation framework into the application of HMMs for behavioral classification is fundamental for generating biologically plausible and scientifically rigorous results. By systematically verifying the data and model, analytically validating state distinction, and crucially, establishing biological meaning through controlled experiments, researchers can confidently use HMMs to uncover the complex dynamics of animal behavior. This robust approach is indispensable for preclinical research and drug development, where accurate behavioral phenotyping is critical for evaluating therapeutic efficacy and safety.
Benchmarking HMM Performance Against Alternative Classification Methods
Comparative Framework: HMMs vs. Machine Learning Classifiers
In the field of movement ecology and behavioral neuroscience, the accurate classification of animal behavior from tracking data is a fundamental challenge. Hidden Markov Models (HMMs) represent a powerful statistical framework for decoding the latent behavioral states that underlie observed movement patterns [15]. These models are premised on the concept that an animal's movement trajectory is a manifestation of a finite number of underlying, and often unobservable, behavioral states such as foraging, traveling, and resting [18] [15]. The core strength of HMMs lies in their ability to model sequential, time-series data where the system being studied—animal behavior—is assumed to be a Markov process, meaning the future state depends only on the present state [64].
The objective of this document is to provide a structured, comparative framework for researchers applying HMMs and other machine learning classifiers to animal tracking data. While other classifiers, notably Support Vector Machines (SVMs), are established as a gold standard for many discrete classification tasks in neuroinformatics and movement analysis, the choice of classifier is highly dependent on the specific research question and data characteristics [65]. This document will detail the theoretical underpinnings, provide direct performance comparisons, and outline robust experimental protocols to guide scientists in selecting and implementing the most appropriate analytical tool for their research on animal behavior.
Theoretical Foundation and Comparative Analysis
Core Concepts of Hidden Markov Models
An HMM is a probabilistic model that describes a system which is assumed to be a Markov process with unobserved (hidden) states. It is defined by two core stochastic processes: a state transition process that is hidden from the observer, and an observation process that is dependent on the hidden state [15] [66]. The model is characterized by three fundamental elements:
- Hidden States (Xt): The true, unobserved behavioral states (e.g., resting, foraging, traveling) at time t.
- Observations (Et): The data that can be measured (e.g., step length, turning angle, sensor data) which are probabilistic functions of the hidden states.
- Model Parameters (λ): The initial state distribution (δ), the state transition probability matrix (A), and the emission probability matrix (B), which defines the likelihood of an observation given a hidden state [15] [64].
The joint probability of a sequence of hidden states and observations can be expressed as: P (X1, ..., XN, E1, .. , EN) = P (X1) P (E1|X1) ∏t=2N P (Xt|Xt-1) P (Et|Xt) [64].
HMMs are a type of generative model, as they learn the joint probability distribution P(Y, X) of the hidden states and the observed sequence [66]. This contrasts with discriminative models, which model the conditional probability P(Y|X) directly.
HMMs vs. Alternative Machine Learning Classifiers
Different classifier paradigms offer distinct advantages and limitations, making them suitable for different aspects of behavioral classification.
Table 1: Comparative Analysis of HMMs and Other Prevalent Classifiers
| Classifier | Model Type | Key Principle | Strengths | Weaknesses | Ideal Use-Case |
|---|---|---|---|---|---|
| Hidden Markov Model (HMM) | Generative | Models latent state sequence & observations via joint probability [66]. | Natural handling of sequential data; models temporal dynamics; probabilistic output [15] [64]. | Strict independence assumptions; target function (joint P) doesn't match prediction goal (conditional P) [66]. | Classifying behavioral states from animal paths or bio-logging time series [18] [15]. |
| Support Vector Machine (SVM) | Discriminative | Finds a hyperplane that maximizes margin between classes in feature space. | High accuracy, robust with small training samples, handles high-dimensional features well [65]. | Less natural for sequential data; standard formulation is static (no temporal context). | Distinguishing discrete, non-sequential behaviors based on a feature vector (e.g., movement bout classification) [67] [65]. |
| Conditional Random Field (CRF) | Discriminative | Models conditional probability of state sequence given observation sequence [66]. | Accommodates any context information; addresses label bias problem of MEMM; global optimum [66]. | High computational complexity at training stage; difficult to re-train with new data [66]. | Advanced sequence labeling where rich, overlapping features of the present are critical. |
Quantitative Performance Comparison
Empirical studies across multiple domains provide insight into the relative performance of HMMs against other classifiers.
Table 2: Empirical Performance Comparison in Various Applications
| Application Domain | HMM Performance | Comparative Classifier Performance | Key Findings and Context |
|---|---|---|---|
| Surfing Activity Recognition [67] | 91.4% classification accuracy | SVM: 83.4% accuracy | HMM's superior handling of time-varying motions from a single IMU sensor. |
| ECoG Finger Movement Classification [65] | Up to ~90% accuracy (with constraints) | SVM: Up to ~90% accuracy | Comparable accuracy achieved; performance gain for HMMs (up to 6%) came from model constraints and feature selection. |
| Animal Behavior Inference (Seabirds) [18] | Accuracy: 0.77 ± 0.01 (unsupervised) → 0.85 ± 0.01 (semi-supervised) | N/A (Internal validation) | Demonstrates significant improvement in HMM accuracy using a small subset (9%) of known behaviors for semi-supervision. |
A key finding from comparative studies is that decoding optimization is often more dependent on feature extraction and selection than on the choice of classifier itself [65]. Furthermore, HMM performance can be significantly enhanced through semi-supervision, where a small subset of data with known behaviors is used to inform the model, increasing accuracy as demonstrated in animal tracking studies [18].
Experimental Protocols for Behavioral Classification
Protocol 1: Building an HMM for Animal Tracking Data
This protocol details the process of applying an HMM to animal GPS tracking data to infer latent behavioral states, based on established methodologies in movement ecology [18] [15].
1. Data Preprocessing and Movement Metric Calculation
- Input: Raw GPS tracking data (e.g., timestamped latitude/longitude coordinates).
- Step 1: Data Cleaning. Filter out obvious GPS fix errors based on speed and location thresholds.
- Step 2: Calculate Step Lengths. Compute the distance between consecutive GPS fixes. This represents the animal's speed if sampling intervals are regular.
- Step 3: Calculate Turning Angles. Compute the relative turning angle (in radians) between every three consecutive GPS fixes. This metric represents the tortuosity of the path.
- Output: A bivariate time series of step lengths and turning angles for each individual track.
2. Model Fitting and State Inference
- Step 4: Define Model Structure. Specify the number of hidden behavioral states (N). For a starting point, N=3 (e.g., Resting, Foraging, Traveling) is common [18].
- Step 5: Initialize Parameters. Provide initial estimates for the transition probability matrix (A) and the emission probability parameters. For step lengths, a Gamma distribution is typically used; for turning angles, a von Mises distribution is appropriate [15].
- Step 6: Train the HMM. Use the Expectation-Maximization (EM) algorithm, also known as the Baum-Welch algorithm in the context of HMMs, to find the model parameters that maximize the likelihood of the observed data [64].
- Step 7: Decode Hidden States. Use the Viterbi algorithm to find the most probable sequence of hidden behavioral states given the fitted model and the observed data [6].
3. Validation and Interpretation
- Step 8: Validate States. Correlate inferred states with auxiliary data streams if available (e.g., accelerometry for fine-scale movement, wet-dry sensors for immersion, TDR for dives) [18]. Cross-validation with a manually annotated subset of data is highly recommended.
- Step 9: Interpret and Apply. Assign ecological meaning to the states based on their characteristic movement patterns (e.g., short steps and high turning angles often indicate foraging) and proceed with downstream analyses.
Protocol 2: A Comparative Analysis Framework
This protocol outlines a rigorous methodology for directly comparing the performance of HMMs against discriminative classifiers like SVMs on the same behavioral dataset, adapted from neuroscience research [65].
1. Experimental Design and Data Preparation
- Task: Select a well-defined behavioral classification task (e.g., finger movement from ECoG [65], or specific animal behaviors from tracking data).
- Data Splitting: Partition the dataset into training, validation, and test sets. Use k-fold cross-validation (e.g., 5-fold) for robust performance estimation [67] [65].
- Labeling: Ensure each trial or track segment has a ground-truth behavioral label.
2. Feature Engineering and Selection
- Feature Extraction: From the raw data (e.g., ECoG signals or GPS tracks), extract a comprehensive set of features. These may include:
- Time-domain features: Step length, velocity, acceleration.
- Frequency-domain features: Spectral power in specific bands (e.g., high gamma oscillations for ECoG) [65].
- Path-level features: Tortuosity, net displacement.
- Feature Selection: Apply feature selection techniques (e.g., filter methods, wrapper methods) to identify the most discriminative feature subset for the task. This step is critical for both HMM and SVM performance [65].
3. Classifier Training and Optimization
- HMM Setup and Training:
- Define the HMM topology (e.g., Bakis model for left-right transitions, or ergodic).
- Consider adding constraints to the transition matrix to reflect known behavioral persistence [65].
- Train using the Baum-Welch algorithm on the training set.
- SVM Setup and Training:
- Select a kernel (e.g., linear or Radial Basis Function).
- Optimize hyperparameters (e.g., regularization parameter C, kernel coefficient gamma) using the validation set.
- Train the optimized SVM on the training set.
4. Evaluation and Comparison
- Performance Metrics: Evaluate both classifiers on the held-out test set using accuracy, precision, recall, F1-score, and confusion matrices.
- Statistical Analysis: Perform statistical tests to determine if performance differences are significant.
- Qualitative Analysis: Examine the temporal coherence of the classified sequences. HMMs may produce smoother, more biologically plausible state sequences.
The Scientist's Toolkit: Research Reagent Solutions
This section catalogs the essential hardware, software, and data resources required for executing the experimental protocols outlined in this document.
Table 3: Essential Research Reagents and Resources
| Category | Item | Specification / Example | Primary Function |
|---|---|---|---|
| Data Acquisition | GPS Loggers | CatLog Gen2, Axytrek loggers [18] | High-frequency recording of animal location. |
| Bio-logging Sensors | Wet-dry sensors, Accelerometers, Time Depth Recorders (TDR) [18] | Collects auxiliary data for behavior validation (e.g., immersion, activity, diving). | |
| Electrocorticography (ECoG) | Subdural electrode grids (e.g., 8x8, 1cm spacing) [65] | Records high-quality neural signals for decoding movement intent. | |
| Software & Libraries | R Statistical Environment | moveHMM, momentuHMM, swim packages [18] [15] |
Provides specialized functions for fitting HMMs to animal tracking data. |
| Python Ecosystem | hmmlearn, scikit-learn (for SVM) |
Offers flexible, general-purpose ML and HMM implementations. | |
| TMB (Template Model Builder) | R package [15] | Enables fast maximum likelihood estimation for complex models. | |
| Computational Methods | Baum-Welch Algorithm | An EM algorithm for HMMs [6] [64] | Iteratively learns optimal HMM parameters from data. |
| Viterbi Algorithm | Dynamic programming algorithm [6] | Finds the single best sequence of hidden states. | |
| Kernel Methods | Linear, RBF (for SVM) [65] | Maps features to a higher-dimensional space to find a separating hyperplane. |
Cross-Validation Approaches for Ground-Truthing Behavioral Inference
The inference of animal behavior from movement data, particularly using Hidden Markov Models (HMMs), has become a fundamental methodology in movement ecology, conservation biology, and neuroscience [68] [10] [69]. These statistical models interpret raw movement metrics (e.g., step length and turning angle) as manifestations of underlying, unobserved behavioral states [4]. However, the ecological validity of these inferred states hinges on their accurate correspondence to actual behaviors, making robust cross-validation against ground-truth data an essential step in the analytical pipeline [68] [16]. Without validation, behavioral classifications may be statistically coherent but ecologically misleading, potentially compromising conservation decisions or scientific conclusions based on them [16].
This application note synthesizes current methodologies for ground-truthing HMM-based behavioral inferences. We provide a structured overview of available techniques, present quantitative performance data, and detail experimental protocols for implementing these validation approaches. The guidance is intended for researchers seeking to ensure that their models accurately reflect biological reality, thereby strengthening the foundation for subsequent ecological interpretation and application.
The performance of HMMs in behavioral classification varies significantly across species, contexts, and data modalities. The following tables summarize key performance metrics and factors influencing validation outcomes from recent studies.
Table 1: Reported Performance of HMMs in Behavioral Classification
| Species/Context | Behavioral States | Accuracy/Performance Notes | Source |
|---|---|---|---|
| Seabirds (Terns) | Foraging, Flying, Resting | 71-87% (chick-rearing); 54-70% (incubation) | [68] |
| Green Sea Turtles | Migration, Foraging, Resting | Effective state identification; nuance dependent on time step (1h, 4h, 8h) and method (HMM, M4, MPM) | [16] |
| Mouse Visual Cliff Test | Resting, Exploring, Navigating | Successful state identification and dynamic transition tracking in WT vs. RD mice | [10] [3] |
| Bio-logger Benchmark (BEBE) | Various across 9 taxa | Deep Neural Networks generally outperformed classical ML methods across all datasets | [29] |
Table 2: Factors Influencing Validation Outcomes
| Factor | Impact on Validation/Inference | Recommendation |
|---|---|---|
| Temporal Scale | Coarser scales smooth behavioral transitions; finer scales may capture more states but introduce noise [16]. | Align data resolution with the temporal scale of the behaviors of interest [16]. |
| Model Selection | HMM, M4, and MPM models can produce different behavioral estimates and interpretations from the same data [16]. | Select a model whose assumptions align with data properties and biological knowledge [16]. |
| Data Autocorrelation | Ignoring within-state autocorrelation in high-resolution data degrades decoding performance [4] [70]. | Use autoregressive HMMs (AR1) for high-frequency data [4] [70]. |
| Ground-Truth Quality | Accuracy depends on the "gold standard" used for validation (e.g., direct observation vs. sensor data) [68] [29]. | Use the most direct validation method feasible; report limitations [68]. |
Experimental Protocols for Ground-Truthing
Direct Observation and Visual Tracking
This protocol uses direct human observation to create a ground-truthed dataset for validating behaviors inferred from movement data, as applied in seabird studies [68].
Workflow Overview:
Materials and Equipment:
- Animal-borne GPS Logger: To collect high-resolution location data.
- Rigid-hulled Inflatable Boat: For following individuals in marine environments [68].
- Portable Computer/GPS Unit: To record the boat's track as a proxy for animal movement.
- Standardized Ethogram: A predefined list of behaviors with clear operational definitions.
- Audio Recorder or Data Logger: For real-time vocal annotation of observed behaviors.
Procedure:
- Tagging: Deploy GPS loggers on target animals. The sampling frequency should be set to match the planned observational interval.
- Visual Tracking: Track the tagged individual from a vessel, maintaining a consistent distance (e.g., 50–100 m) to minimize disturbance [68].
- Synchronized Data Recording:
- Record the boat's GPS track at the same frequency as the animal's logger.
- A trained observer continuously calls the animal's behavior based on the ethogram (e.g., "foraging," "flying," "resting") into an audio recorder. Note the universal coordinated time (UTC) for the start and end of each behavioral bout.
- Data Processing:
- Transcribe the audio recordings into a time-stamped behavioral log.
- Synchronize the animal's GPS track, the boat's GPS track (proxy), and the behavioral log using UTC timestamps.
- HMM Development and Validation:
- Calculate movement metrics (step lengths and turning angles) from the proxy movement track.
- Fit an HMM to these metrics to infer behavioral states.
- Create a confusion matrix to compare the HMM-inferred states against the manually recorded behaviors from the visual track to quantify accuracy [68].
Multi-Sensor Validation with Bio-Loggers
This protocol uses data from complementary sensors, such as accelerometers, to validate behaviors inferred from GPS data alone [29].
Workflow Overview:
Materials and Equipment:
- Multi-sensor Bio-logger: A device containing a GPS and a tri-axial accelerometer (and/or other sensors like gyroscopes or depth sensors).
- Annotation Software: Tools for visualizing and labeling high-frequency sensor data (e.g., the BEBE framework [29]).
- Machine Learning Libraries: Software (e.g., R, Python) with support for random forests or deep neural networks.
Procedure:
- Data Collection: Deploy multi-sensor bio-loggers on the study animals. The accelerometer should be set to a high frequency (e.g., 10–20 Hz) sufficient to capture posture and fine-scale movements.
- Sensor-based Annotation:
- Model Training: Train a supervised machine learning model (e.g., a Random Forest or a Deep Neural Network) using the annotated accelerometer data to classify behaviors [29].
- Behavioral Prediction and Validation:
- Use the trained model to predict behaviors for the entire dataset based on the accelerometer data. This serves as a high-resolution validation dataset.
- Fit an HMM to the GPS-derived movement metrics.
- Statistically compare the HMM-inferred states with the sensor-predicted behaviors to assess congruence.
Benchmarking Against a Common Framework
This protocol involves using a standardized public benchmark, like the Bio-logger Ethogram Benchmark (BEBE), to evaluate and compare the performance of HMMs against other machine learning methods [29].
Materials and Equipment:
- BEBE Datasets: Publicly available datasets from the BEBE benchmark, which include annotated bio-logger data from multiple taxa [29].
- Computational Resources: Adequate hardware and software for running HMMs and other machine learning models.
Procedure:
- Data Acquisition: Download one or more datasets from the BEBE benchmark.
- Model Implementation: Apply your HMM analytical pipeline to the benchmark's sensor data (e.g., accelerometry).
- Performance Evaluation: Use the benchmark's provided evaluation code and metrics to quantify your HMM's accuracy in predicting the ground-truthed behaviors in the dataset.
- Comparative Analysis: Compare the performance of your HMM against the baseline results provided by BEBE, which may include other classical and deep learning methods [29]. This helps contextualize the strengths and weaknesses of your specific HMM implementation.
The Scientist's Toolkit
Table 3: Essential Research Reagents and Solutions for Behavioral Validation
| Tool/Solution | Function/Application | Example/Notes |
|---|---|---|
| GPS Bio-loggers | Collects location data at regular intervals to calculate movement metrics. | SPLASH10-F-385A tags used for green sea turtles [16]. |
| Tri-axial Accelerometer | Measures fine-scale dynamic body acceleration to identify specific behaviors. | Often integrated with GPS in bio-loggers; used for supervised learning [29] [69]. |
| DeepLabCut | Open-source pose estimation software for precise tracking from video. | Used to extract body center coordinates in mouse visual cliff tests [10] [3]. |
| Bio-logger Ethogram Benchmark (BEBE) | Public benchmark for comparing behavior classification model performance. | Contains 1654 hours of data from 149 individuals across 9 taxa [29]. |
| Circular Visual Cliff Apparatus | Behavioral testing device for assessing depth perception with reduced corner bias. | 60 cm diameter paper tube enclosure used in mouse studies [10] [3]. |
| Move Persistence Models (MPM) | State-space model estimating a continuous behavioral parameter (move persistence). | Compared against HMMs for identifying fine-scale behaviors [16]. |
| Hidden Markov Model (HMM) Software | Statistical tool for inferring discrete behavioral states from time-series data. | Implemented in R packages (e.g., moveHMM); can be extended with autoregressive components [68] [4]. |
| Autoregressive HMM (AR-HMM) | HMM extension that accounts for autocorrelation in high-resolution data. | Critical for modeling momentum in high-frequency movement tracks [4] [70]. |
Robust validation is not merely an optional step but a critical component in the behavioral inference pipeline. The protocols outlined here—ranging from direct visual tracking to sophisticated multi-sensor benchmarking—provide a pathway for researchers to quantify and improve the accuracy of their HMM-based behavioral classifications. By carefully selecting a validation strategy that aligns with their biological questions, model assumptions, and data properties, scientists can significantly enhance the ecological validity of their inferences. This, in turn, strengthens the scientific and conservation outcomes that depend on a reliable understanding of animal behavior.
The Bio-logger Ethogram Benchmark (BEBE) represents a significant advancement for researchers applying computational methods to classify animal behavior from sensor data [71]. It provides a standardized, publicly available framework to train and evaluate machine learning models, enabling direct comparison of algorithms across a diverse collection of annotated bio-logger datasets [71]. For research focused on Hidden Markov Models (HMMs) and similar probabilistic approaches for classifying animal tracking data, BEBE offers a rigorous and taxonomically diverse testbed to validate methodological innovations against state-of-the-art alternatives [71] [72].
BEBE addresses a critical gap by consolidating 1,654 hours of data from 149 individuals across nine taxa, making it the largest and most diverse public benchmark of its kind [71]. It encompasses data from sensors like tri-axial accelerometers and gyroscopes, with annotated behaviors, a defined classification task, and established evaluation metrics [71].
Table 1: BEBE Benchmark Dataset Composition
| Taxonomic Group | Individuals | Data Hours | Sensor Types | Annotated Behaviors |
|---|---|---|---|---|
| Multiple species across nine taxa | 149 | 1654 | Tri-axial accelerometer, Gyroscope, Environmental sensors | Species-specific ethograms (e.g., foraging, locomotion, resting) |
The benchmark was used to test key hypotheses about machine learning in this domain, revealing that deep neural networks outperformed classical machine learning methods across all nine datasets [71]. Furthermore, a self-supervised learning approach, pre-trained on a large corpus of human accelerometer data, showed superior performance, particularly in low-data scenarios [71].
Table 2: Key Experimental Findings from BEBE
| Hypothesis Tested | Model Classes Compared | Key Result | Implication for HMM Research |
|---|---|---|---|
| H1: Deep learning vs. classical methods | CNN, CRNN vs. Random Forest (rf), GMM, HMM | Deep neural networks outperformed classical methods across all datasets [71]. | Establishes a strong performance baseline that new HMM-based approaches must exceed. |
| H2/H3: Benefits of self-supervised learning | Self-supervised pre-training + fine-tuning vs. models trained from scratch | Self-supervised approach outperformed alternatives, especially with limited annotated data [71]. | Suggests HMMs could be integrated with or fine-tuned from feature extractors pre-trained with self-supervised learning. |
Experimental Protocols for Benchmark Utilization
Protocol 1: Model Training and Evaluation on BEBE
This protocol outlines the procedure for training and evaluating a behavior classification model, such as an HMM, using the BEBE framework [71] [72].
- Environment Setup: Install the BEBE package from its GitHub repository, ensuring compatible versions of Python, PyTorch, and other dependencies are installed, particularly if using GPU acceleration [72].
- Data Acquisition and Partitioning: Download the BEBE datasets. The benchmark is structured for cross-validation, where data is typically split into folds (e.g., folds 1-4 for training/validation and fold 0 for testing) [72].
- Model Configuration: Create a configuration file specifying hyperparameters. For HMMs, this includes the number of hidden states, learning rate, and number of training iterations [72].
- Model Training: Execute the training script. For a cross-validation experiment, run
cross_val_experiment.pywith arguments specifying the experiment directory, dataset path, and model type (e.g.,--model=hmm) [72]. - Model Evaluation: The trained model is used to predict behavioral labels on the held-out test set. Performance is automatically evaluated using metrics like weighted F1-score, which is the primary metric for BEBE, providing a balanced measure of precision and recall across potentially imbalanced behavior classes [71] [72].
- Result Analysis: Review the generated results files for model performance. Results are saved in
final_result_summary.yamland per-individual scores are found infold_$i/test_eval.yaml[72].
Protocol 2: Implementing a Novel HMM for Behavior Classification
This protocol describes the steps to implement and integrate a novel HMM-based classifier into the BEBE codebase for fair comparison with existing models [72].
- Model Class Definition: Create a new model class that inherits from the
BehaviorModelsuperclass defined inBEBE/models/model_superclass.py. This ensures compatibility with the benchmark's training and evaluation pipelines [72]. - Default Configuration: Define a set of default hyperparameters for the new model in a YAML file placed inside the
BEBE/models/default_configs/directory [72]. - Integration into Training Pipeline: Add the new model class to the
BEBE/training/train_model.pyfile so it can be instantiated and called by the main training scripts [72]. - Hyperparameter Optimization: To enable automated hyperparameter tuning, add the new HMM model and the hyperparameters to search over to
BEBE/utils/hyperparameters.py[72]. - Standalone Evaluation: If the model cannot be fully integrated, its predictions can be evaluated by saving them as CSV files and using the
generate_evaluations_standalonefunction inBEBE/evaluation/evaluation.py[72].
The Scientist's Toolkit: Essential Research Reagents
Table 3: Key Computational Tools and Resources for Behavior Classification Research
| Tool/Resource | Type | Function in Research |
|---|---|---|
| BEBE Benchmark | Dataset & Framework | Provides standardized datasets and evaluation code for comparing behavior classification models [71] [72]. |
| Tri-axial Accelerometer | Sensor | Records kinematic data on animal movement in three dimensions, forming the primary data source for many bio-logging studies [71]. |
| Hidden Markov Model (HMM) | Algorithm | A probabilistic model for inferring a sequence of hidden behavioral states from a sequence of observed sensor data [71] [72]. |
| Self-Supervised Learning Model | Algorithm | Leverages large unlabeled datasets for pre-training, improving performance on downstream behavior classification tasks with limited labels [71]. |
| Python/PyTorch/JAX | Software | Core programming languages and libraries for implementing and training modern machine learning models like deep neural networks and HMMs [72]. |
Visual Workflows for Benchmark Application in HMM Research
The following diagrams illustrate the core BEBE workflow and a specific pathway for integrating HMMs, designed using the specified color palette and contrast rules.
BEBE Benchmark Evaluation Workflow
HMM Integration with Feature Learning
Hidden Markov Models (HMMs) have become a fundamental tool for classifying animal behavior from tracking data, but they possess a significant limitation: their geometric state duration distribution. The standard HMM framework assumes that the probability of remaining in a behavioral state decreases exponentially over time, which often contradicts biological reality where animals frequently maintain behaviors like resting, foraging, or traveling for sustained, predictable periods. This limitation becomes particularly problematic when analyzing high-resolution movement data, where the conditional independence assumption of basic HMMs fails to account for the momentum in animal movement, creating substantial model lack of fit [4]. Hidden Semi-Markov Models (HSMMs) address this fundamental constraint by explicitly modeling state persistence, allowing for more accurate and biologically meaningful inference of behavioral sequences from animal tracking data.
The integration of auxiliary sensors has revealed both the promise and limitations of standard HMMs. Research on red-billed tropicbirds demonstrated that even with sophisticated HMM approaches, the identification of certain behaviors like "foraging on the go" in homogenous environments remained challenging, with sensitivity and precision rates as low as 0.37 and 0.06 respectively [18]. These limitations underscore the need for more advanced modeling frameworks like HSMMs that can better capture the temporal structure of animal behavior, particularly for species that don't exhibit clear area-restricted search patterns or that maintain behaviors for consistent durations.
Quantitative Comparison: HMMs vs. HSMMs
Table 1: Performance comparison between HMMs and HSMMs across different tracking scenarios
| Metric | Standard HMM | HSMM | Application Context | Data Requirements |
|---|---|---|---|---|
| State Duration Distribution | Geometric (implicit) | Explicit, user-defined (e.g., Poisson, negative binomial) | All behavioral tracking | None beyond standard tracking |
| Behavior Classification Accuracy | 0.77 ± 0.01 [18] | Improved (theoretical) | Opportunistic foragers in homogeneous environments | GPS with auxiliary sensors |
| Foraging Behavior Sensitivity | 0.37 ± 0.06 [18] | Significantly improved (theoretical) | Tropical seabirds, marine predators | Wet-dry sensors, TDR |
| Within-state Serial Correlation | Poor handling [4] | Excellent handling | High-frequency data (>1Hz) | High-resolution GPS |
| Computational Complexity | Lower | Higher | Large datasets (>400 deployments) | Standard computing resources |
Table 2: Impact of auxiliary data integration on behavioral classification
| Auxiliary Data Type | Behavioral State Informed | Improvement in Classification | Validation Method |
|---|---|---|---|
| Wet-dry Sensors | Resting (on water) | Significant improvement | Saltwater immersion logging |
| Time Depth Recorders (TDR) | Foraging (diving) | Moderate improvement | Dive threshold detection |
| Accelerometers | Multiple states (fine-scale) | Highest potential improvement | Machine learning classification |
| Combined Sensors | Comprehensive behavioral repertoire | Accuracy increase: 0.77 to 0.85 ± 0.01 [18] | Cross-validation with known states |
The quantitative evidence from standard HMM applications clearly demonstrates the need for more sophisticated duration modeling. In the red-billed tropicbird study, even with auxiliary data integration representing 9% of the full dataset, overall model accuracy improved from 0.77 to 0.85, yet foraging behavior specifically remained difficult to identify with low sensitivity and precision [18]. This state-dependent performance variation suggests that explicitly modeling duration could particularly benefit behaviors that occur in sustained bouts with characteristic lengths. Furthermore, for high-resolution data (0.1-10Hz), basic HMMs exhibit substantial lack of fit due to their inability to account for within-state autocorrelation induced by momentum in movement [4], a limitation that HSMMs with autoregressive components are specifically designed to address.
Experimental Protocols for HSMM Implementation
Data Collection and Instrumentation Protocol
Objective: To collect synchronized multi-sensor data for developing and validating HSMMs for animal behavior classification.
Equipment Setup:
- Primary GPS loggers (e.g., CatLog Gen2) programmed at 5-minute intervals for movement trajectory [18]
- Multi-sensor loggers (e.g., Axytrek) recording GPS (5-min), tri-axial accelerometer (25 Hz), and pressure data (1s intervals) [18]
- Wet-dry sensors (e.g., Migrate Technology C330) recording immersion state every 6 seconds [18]
- Deployment on target species during biologically significant periods (incubation, chick-rearing)
Attachment Procedure:
- Secure devices to central tail feathers using Tesa tape for birds [18]
- Ensure total device weight does not exceed 3-5% of animal body mass
- Test instrument functionality pre-deployment and verify data recording
Data Collection Duration:
- Minimum 7-day continuous monitoring recommended to capture behavioral cycles
- Synchronize all sensor clocks to UTC prior to deployment
- Record environmental covariates (time of day, habitat type) concurrent with tracking
Data Preprocessing and Feature Engineering Workflow
Movement Metric Calculation:
- Compute step lengths as Euclidean distances between consecutive GPS positions
- Calculate turning angles in radians from three consecutive locations
- Derive movement tortuosity metrics using First Passage Time analysis
Auxiliary Data Alignment:
- Synchronize accelerometer, TDR, and wet-dry data with GPS timestamps
- For accelerometer data, compute overall dynamic body acceleration (ODBA)
- For TDR data, identify dive events using depth threshold detection
- For wet-dry sensors, classify resting periods based on continuous immersion
Behavioral Labeling for Semi-Supervision:
- Identify known behavioral states from auxiliary sensors:
- Resting: Continuous dry periods >10 minutes (terrestrial) or continuous wet periods with minimal movement (aquatic)
- Foraging: Dive events (TDR) combined with characteristic acceleration signatures
- Traveling: Directed movement with high step length and low turning angle
- Label corresponding GPS fixes with known behaviors for model training
HSMM Implementation and Validation Procedure
Model Specification:
- Define state-dependent distributions for step lengths (Gamma) and turning angles (von Mises)
- Select appropriate duration distributions for each behavioral state (Poisson, negative binomial)
- Incorporate autoregressive components for high-resolution data [4]
Parameter Estimation:
- Implement forward-backward algorithm modified for explicit duration modeling
- Use expectation-maximization or direct numerical maximization for likelihood optimization
- Employ lasso regularization for automatic order selection of autoregressive components [4]
Model Validation:
- Perform k-fold cross-validation using temporally distinct data segments
- Calculate confusion matrices comparing model predictions to auxiliary sensor-derived behaviors
- Compute state-specific sensitivity, specificity, and precision metrics
- Compare HSMM performance against standard HMM benchmarks
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential research materials and analytical tools for HSMM implementation
| Tool Category | Specific Products/Functions | Research Application | Key Features |
|---|---|---|---|
| Tracking Hardware | CatLog Gen2 GPS, Axytrek multi-sensor loggers, Migrate Technology geolocators | Animal movement data acquisition | 5-min GPS resolution, 25Hz accelerometry, wet-dry sensing [18] |
| Analytical Software | R packages: momentuHMM, moveHMM |
HSMM implementation & analysis | Explicit duration modeling, auxiliary data integration [18] [4] |
| Behavioral Validation Sensors | Time Depth Recorders (TDR), tri-axial accelerometers, wet-dry sensors | Ground-truthing behavioral states | Dive detection, fine-scale movement capture, immersion logging [18] |
| Computational Infrastructure | High-performance computing clusters, cloud computing resources | Handling large tracking datasets (>400 deployments) | Parallel processing for likelihood optimization [18] |
| Data Visualization Tools | R ggplot2, Python matplotlib, custom movement visualization software | Exploration of behavioral classification results | Track animation, state probability visualization |
Advanced Methodological Considerations
Autoregressive Components for High-Resolution Data
For high-resolution movement data (≥1Hz), standard HSMMs may still insufficiently capture the within-state serial correlation caused by movement momentum. The autoregressive HSMM framework addresses this limitation by incorporating lagged observations into the state-dependent distributions [4]. This approach models the mean step length as a function of previous observations:
[ \mu{t,j}^{\text{step}} = \sum{k=1}^{pj^{\text{step}}}\phi{j,k}^{\text{step}} x{t-k}^{\text{step}} + \Bigl(1-\sum{k=1}^{pj^{\text{step}}}\phi{j,k}^{\text{step}}\Bigr) \mu_j^\text{step} ]
where (pj^{\text{step}}) represents the autoregressive order for state j, and (\phi{j,k}^{\text{step}}) are the autoregressive parameters. Similar structures can be applied to turning angles, creating a comprehensive framework that accounts for both behavioral persistence and physical momentum in animal movement.
Semi-Supervised Learning with Limited Auxiliary Data
The integration of partially labeled data through semi-supervision significantly enhances HSMM performance, particularly for species with subtle behavioral signatures. The protocol involves several stages:
This approach leverages a small subset of informed positions (representing only 9% of the full dataset in the tropicbird study) to significantly improve overall behavioral classification accuracy from 0.77 to 0.85 [18]. The method is particularly valuable for identifying rare but ecologically significant behaviors that might otherwise be misclassified.
State-Specific Duration Distributions
The selection of appropriate duration distributions represents a critical modeling decision in HSMM implementation. Different behavioral states often exhibit distinct temporal characteristics:
- Resting states: Typically follow negative binomial distributions with moderate overdispersion
- Foraging bouts: Often best modeled with zero-inflated Poisson distributions to account for brief, unsuccessful attempts
- Traveling segments: Frequently demonstrate Weibull distributions with increasing hazard functions
Model selection should be guided by both biological plausibility and statistical criteria such as AIC or BIC, with cross-validation to assess predictive performance on temporally held-out data.
Hidden Semi-Markov Models represent a significant advancement over standard HMMs for animal behavior classification by explicitly accounting for behavioral state duration. The integration of auxiliary sensor data, semi-supervised learning approaches, and autoregressive components for high-resolution data creates a robust framework for addressing the complex temporal structure of animal behavior. As biologging technologies continue to evolve, producing increasingly rich multi-sensor datasets, HSMMs provide the statistical sophistication necessary to extract meaningful biological inference from these complex data streams. Future methodological developments will likely focus on integrating deep learning approaches with HSMM frameworks, enabling even more precise identification of behaviors from multi-modal sensor data [73].
Automated analysis of animal behavior represents a complex pattern recognition challenge at the intersection of neuroscience, ethology, and computer science. While deep learning has revolutionized the field, several compelling alternatives offer unique advantages for specific research contexts, particularly when classifying animal behavior from tracking data. The growing interest in explainable machine intelligence requires experimental environments and diagnostic datasets to analyze existing approaches and drive progress in pattern analysis [74]. This is especially relevant for research and drug development professionals who require both high accuracy and methodological transparency.
The fundamental challenge lies in transforming raw positional data from animal tracks into meaningful behavioral states such as resting, foraging, or traveling. Although deep neural networks excel at processing unstructured data like images, audio, and text through non-linear processing and backpropagation [75], they face significant limitations in scenarios with limited training data, computational constraints, or requirements for interpretable models. This protocol explores efficient shallow learning architectures, Hidden Markov Models (HMMs), and hybrid approaches as viable alternatives for complex pattern recognition in behavioral classification, with specific application to the context of classifying animal behavior from tracking data.
Quantitative Comparison of Pattern Recognition Approaches
Table 1: Performance Characteristics of Pattern Recognition Approaches
| Model Type | Best Application Context | Key Strengths | Key Limitations | Reported Accuracy/Performance |
|---|---|---|---|---|
| Shallow Learning (Generalized LeNet) | CIFAR-10 database classification [76] | Power-law error decay with increased filters; Lower computational complexity per epoch [76] | Heavy computational task for large filter numbers; Requires exhaustive hyperparameter search [76] | Error rates decay as power law: ( \epsilon(d1) = \frac{A}{(d1)^\rho} ) with ( \rho \sim 0.41 ); For ( d_1 = 27 ), ( \epsilon \sim 0.137 ) [76] |
| Hidden Markov Models (HMMs) | Animal behavior classification from tracking data [18] [15] | Interpretable, probabilistic foundation; Works with small datasets; Fast inference [77] [75] | Struggles with long-range dependencies; Limited capacity for high-dimensional data [77] [75] | Overall accuracy improved from 0.77±0.01 to 0.85±0.01 with semi-supervision; Low foraging precision: 0.06±0.01 [18] |
| Hybrid Models (HMM + Neural Networks) | Speech recognition, gesture recognition [77] | Combines probabilistic reasoning with neural feature extraction; More explainable than black-box deep learning [77] | Implementation complexity; Potential integration challenges between components [77] [75] | In healthcare, enabled more explainable models for tracking disease progression compared to black-box deep learning [77] |
Table 2: Computational Requirements and Implementation Considerations
| Model Type | Hardware Requirements | Training Data Needs | Implementation Frameworks | Inference Speed |
|---|---|---|---|---|
| Shallow Learning (Generalized LeNet) | Standard GPU (e.g., NVIDIA GeForce 1080/2080) [78] | Moderate data requirements | TensorFlow, PyTorch, Keras [75] | Fast forward pass; Quadratic scaling with filters [76] |
| Hidden Markov Models (HMMs) | Standard laboratory desktop or personal computer [79] | Works with small/medium datasets [77] [75] | moveHMM, momentuHMM in R [18] [15]; hmmlearn in Python [75] | Fast inference compared to deep learning [77] [75] |
| Animal Tracking Software (AlphaTracker) | GPU with ≥8 GB memory recommended; ≥32 GB system RAM [78] | Labeled data for training detection model | AlphaTracker (Python/PyTorch) [78] | Several-fold real-time processing possible [79] |
Experimental Protocols for Behavioral Classification
Protocol 1: Semi-Supervised HMM for Animal Behavior Classification
Application Context: Classifying behavior from GPS tracking data of animals, particularly useful for species exhibiting "looping trips" through homogeneous environments where traditional movement metrics struggle to distinguish behaviors [18].
Materials and Equipment:
- GPS loggers (e.g., CatLog Gen2 GPS) programmed at 5-minute intervals [18]
- Auxiliary sensors: Accelerometers (e.g., Axytrek loggers), wet-dry sensors (e.g., Migrate Technology geolocators), Time Depth Recorders (TDR) [18]
- Software: R packages
moveHMMormomentuHMM[18] [15] - Computer: Standard laboratory desktop or personal computer sufficient [79]
Procedure:
- Data Collection: Deploy GPS loggers with auxiliary sensors on a subset of animals (9% of dataset proved effective) [18]
- Sensor Data Processing:
- Convert wet-dry data to resting behavior classifications
- Extract foraging from dive events (TDR) or specific acceleration patterns
- Identify traveling from directed movement with consistent speed [18]
- Movement Metric Calculation:
- Calculate step lengths (distance between consecutive positions)
- Compute turning angles (change in direction between steps) [18]
- HMM Training with Semi-Supervision:
- Model Validation:
- Assess overall accuracy, sensitivity, specificity, and precision for each behavior
- Pay particular attention to challenging discriminations (e.g., foraging vs. traveling in homogeneous environments) [18]
Troubleshooting Tips:
- For low precision in foraging behavior, consider incorporating habitat data or adjusting state definitions
- If model fails to converge, check for sufficient contrast in movement metrics between states
- When working with species in homogeneous environments, expect lower foraging behavior precision [18]
Protocol 2: Shallow Neural Networks for Efficient Pattern Recognition
Application Context: Image-based behavior classification where deep learning computational requirements are prohibitive, but performance must remain high.
Materials and Equipment:
- Camera system: Logitech C930e or similar (≥1080p recommended) [78]
- Computer with GPU (NVIDIA GeForce 1080/2080 or equivalent with ≥8 GB memory) [78]
- Software: Python 3.8+, PyTorch 1.8.0+, AlphaTracker for multi-animal tracking [78]
Procedure:
- Data Preparation:
- Architecture Configuration:
- Model Training:
- Performance Validation:
- Monitor error rate decay relative to power law expectation: ( \epsilon(d1) = \frac{A}{(d1)^\rho} ) with ( \rho \sim 0.41 ) [76]
- Compare computational complexity against deep learning alternatives
Troubleshooting Tips:
- If training is computationally intensive, use down-sampling to reduce file size [79]
- For slow processing, store videos on local computer drives rather than network drives [79]
- With limited training data, employ data augmentation or transfer learning approaches
Workflow Visualization for Behavioral Classification
Behavioral Classification Workflow: This diagram outlines the comprehensive process for classifying animal behavior from tracking data, integrating both primary GPS data and auxiliary sensors across multiple modeling approaches.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Essential Research Reagents and Materials for Behavioral Tracking and Analysis
| Item Name | Specifications/Examples | Primary Function | Implementation Notes |
|---|---|---|---|
| GPS Tracking Loggers | CatLog Gen2 GPS (18g) [18] | Records animal positions at programmed intervals | Weigh <3% of animal body mass; 5-minute intervals effective for behavior classification [18] |
| Multi-Sensor Loggers | Axytrek loggers (17g) with accelerometer, GPS, pressure sensor [18] | Provides complementary behavioral data streams | Records acceleration (25Hz), pressure (1s intervals), GPS (5-min) [18] |
| Wet-Dry Sensors | Migrate Technology C330 geolocators (3.3g) [18] | Detects saltwater immersion for aquatic species | Registers wet/dry status every 6 seconds; minimal mass (0.5% body weight) [18] |
| Hidden Markov Model Software | moveHMM, momentuHMM (R) [18] [15] | Implements HMM for behavioral classification | Handles multiple data streams at different resolutions; includes visualization tools [18] |
| Multi-Animal Tracking Software | AlphaTracker [78] | Markerless pose estimation and tracking | Based on AlphaPose; requires GPU for training; handles near-identical animals [78] |
| Basic Behavior Tracking | ezTrack [79] | Open-source video analysis | No GPU required; compatible with standard video formats; two modules: Location Tracking and Freeze Analysis [79] |
For researchers classifying animal behavior from tracking data, the selection of pattern recognition approaches should be guided by specific experimental constraints and objectives. Hidden Markov Models offer exceptional utility when working with traditional tracking data supplemented by limited auxiliary sensor information, particularly when interpretability is valued and movement patterns follow theoretically predictable structures [18] [15]. Shallow learning architectures provide a compelling alternative to deep learning when computational resources are constrained but performance requirements remain stringent, exhibiting power-law error reduction with increasing model capacity [76]. Hybrid approaches that combine probabilistic models with neural feature extractors represent an emerging frontier that balances interpretability with representational power [77] [75].
Critical to success is the recognition that all automated behavior analysis is fundamentally limited by the quality and comprehensiveness of training data [80]. Multidisciplinary teams incorporating ethologists, computer scientists, and domain specialists are essential for developing robust classification systems that generalize beyond specific experimental conditions. By strategically selecting pattern recognition approaches aligned with experimental constraints, behavioral researchers can advance our understanding of animal behavior while maintaining methodological rigor and interpretability.
In the analysis of animal behavior using Hidden Markov Models (HMMs), accurately quantifying classification performance is paramount. HMMs function as dual-component systems, comprising a hidden state process that represents underlying behavioral states (e.g., resting, foraging, traveling) and an observed process typically based on movement metrics like step length and turning angle [9]. The fundamental challenge lies in evaluating how well the model's predicted behavioral states align with the ground truth. Proper evaluation metrics are not merely diagnostic tools; they are essential for validating model outputs, guiding model selection, and ensuring that subsequent ecological interpretations—such as identifying critical habitats or understanding behavioral responses to environmental change—are built upon a reliable foundation [18] [29]. The selection of appropriate accuracy metrics becomes particularly critical when dealing with imbalanced datasets, a common scenario in animal behavior studies where animals often spend disproportionate amounts of time in different behavioral states [81].
Core Accuracy Metrics for Behavioral Classification
The evaluation of a classification model typically begins with a confusion matrix, a fundamental table that cross-tabulates predicted behavioral states against true (observed) states [82]. From this matrix, a suite of core metrics can be derived, each offering a unique perspective on classifier performance. The most straightforward metric is Accuracy, which measures the overall proportion of correct predictions among all predictions. However, accuracy can be highly misleading when the class distribution is imbalanced, as it may be skewed by high performance on the most frequent class [82] [81].
For a more nuanced assessment, especially for specific behavioral states of interest, researchers should employ metrics that are calculated per-class:
- Sensitivity (Recall or True Positive Rate): Measures the proportion of actual positives that are correctly identified. For example, it quantifies how well the model detects true "foraging" events [82].
- Specificity (True Negative Rate): Measures the proportion of actual negatives that are correctly identified. It assesses the model's ability to rule out a behavior when it is not occurring [82].
- Precision (Positive Predictive Value): Measures the proportion of positive predictions that are actually correct. A high precision for "foraging" means that when the model predicts foraging, it is likely to be true [82].
Two composite metrics that balance these aspects are also widely used:
- F1-Score: The harmonic mean of precision and recall, providing a single metric that balances both concerns. It is especially useful when a balance between false positives and false negatives is sought [82].
- Matthew's Correlation Coefficient (MCC): A correlation coefficient between the observed and predicted classifications that returns a value between -1 and +1. A coefficient of +1 represents a perfect prediction, 0 no better than random, and -1 total disagreement. MCC is considered a balanced measure even when classes are of very different sizes [82] [81].
Table 1: Core Metrics for Binary Classification of a Single Behavioral State (e.g., Foraging vs. Non-Foraging)
| Metric | Formula | Interpretation | Focus |
|---|---|---|---|
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | Overall correctness across all states | Overall Model |
| Sensitivity/Recall | TP / (TP + FN) | Ability to correctly identify the state | False Negatives |
| Specificity | TN / (TN + FP) | Ability to correctly reject other states | False Positives |
| Precision | TP / (TP + FP) | Reliability of a positive prediction | False Positives |
| F1-Score | 2 × (Precision × Recall) / (Precision + Recall) | Balance between Precision and Recall | Combined Balance |
| MCC | (TP×TN - FP×FN) / √((TP+FP)(TP+FN)(TN+FP)(TN+FN)) | Overall correlation between true and predicted classes | Overall Balance |
TP: True Positive, TN: True Negative, FP: False Positive, FN: False Negative.
Aggregation Strategies for Multi-Class Behavioral States
In behavioral studies with more than two states (e.g., Resting, Exploring, Navigating), the per-class metrics must be aggregated into a single score for model comparison. The two primary strategies for this are macro-averaging and micro-averaging [82].
Macro-averaging computes the metric independently for each class and then takes the arithmetic mean. This approach treats all classes equally, regardless of their prevalence. Consequently, the performance on a rare but ecologically critical behavior (e.g., a low-prevalence "predation attempt" state) has the same influence on the final score as a high-prevalence "resting" state. This makes macro-averaging suitable when all behavioral states are considered equally important [82] [81].
Micro-averaging aggregates the contributions of all classes by calculating the metric from a global confusion matrix, effectively summing the TP, FP, etc., across all classes first. This approach weights each class by its prevalence, meaning that the performance on more frequent classes will dominate the final score. It is equivalent to overall accuracy in a multi-class setting [82].
The choice between macro and micro F1-score, for instance, depends on the research question. If the goal is to ensure good performance across all behaviors, even rare ones, macro F1 is preferable. If the overall performance across the entire dataset is the primary concern, micro F1 (or accuracy) may be suitable [81].
Table 2: Multi-class Averaging Strategies for Behavioral State Classification
| Averaging Method | Calculation | Interpretation | Use Case |
|---|---|---|---|
| Macro | Arithmetic mean of the per-class metric scores. | Gives equal weight to each behavioral state. | All states are of equal biological importance. |
| Micro | Metric calculated from a pool of all classes' contributions. | Gives equal weight to each individual observation (prevalence-dependent). | Overall dataset performance is the key metric. |
| Weighted | Mean of per-class scores, weighted by each class's support (number of true instances). | Balances the importance of a class with its frequency. | A compromise between macro and micro. |
Experimental Protocol for Metric Validation in HMMs
Workflow for Model Training and Evaluation
The following protocol outlines a robust workflow for training an HMM on animal tracking data and systematically evaluating its classification performance using the described metrics. This workflow can be adapted for both fully supervised and semi-supervised learning scenarios [18].
Diagram 1: Workflow for HMM evaluation using accuracy metrics.
Step-by-Step Protocol
Step 1: Data Collection and Annotation
- GPS Tracking Data: Collect regular-interval location data (
x,ycoordinates). From this, derive movement features: step length (l_t = straight-line distance between consecutive locations) and turning angle (φ_t = change in direction between consecutive steps) [9] [3]. - Auxiliary Sensor Data (for Ground Truth): Simultaneously deploy auxiliary sensors on a subset of individuals to generate validated behavioral labels. This is critical for metric calculation.
- Accelerometers: Classify behaviors like flapping, walking, or resting based on signal variance and periodicity [83] [29].
- Time-Depth Recorders (TDR): Identify diving and foraging events in marine species [18].
- Wet-Dry Sensors: Determine when an animal is on water vs. land, inferring resting or swimming [18].
- Direct Observation: Use video recording or human observers to create a labeled ethogram [84].
Step 2: Feature Engineering
- Clean the GPS data and calculate the step lengths and turning angles. These form the bivariate observation series
Y_t = (l_t, φ_t)for the HMM [9]. - For accelerometer or other high-frequency data, calculate summary statistics (e.g., mean, variance, correlation) over windows corresponding to the GPS fix interval [29].
Step 3: Data Partitioning
- Split the annotated dataset into training and testing sets. A common split is 70/30 or 80/20. Ensure that data from the same individual is not in both sets, or use leave-one-individual-out cross-validation to avoid pseudoreplication and overoptimistic performance estimates [29].
Step 4: HMM Training and Prediction
- Fit the HMM to the training data's observation series. The model learns:
- Use the trained model to predict the most likely sequence of hidden states (the Viterbi algorithm) for the held-out test data.
Step 5: Generate the Confusion Matrix
- Create a
K x Kconfusion matrix, whereKis the number of behavioral states. - Rows represent the ground-truth labels (from auxiliary sensors), and columns represent the HMM-predicted labels. The diagonal contains the correct predictions (True Positives for each class) [82].
Step 6: Calculate Evaluation Metrics
- Using the confusion matrix, compute the suite of metrics outlined in Sections 2 and 3.
- Critical Note on Metric Selection: Do not select a metric based on the test set results. The choice of metric (e.g., macro F1 vs. MCC) should be justified a priori based on the biological question and class imbalance [81]. The test set is only for obtaining a final, unbiased estimate of performance.
Step 7: Model Selection and Validation
- Compare different models (e.g., with varying numbers of states
K) based primarily on the pre-selected accuracy metric(s) from the validation set. - The final model's performance is reported based on its evaluation on the untouched test set. This protocol ensures an unbiased assessment of how the model will generalize to new data [82] [29].
Advanced Applications: Semi-Supervised Learning with Auxiliary Data
A powerful application of accuracy metrics is in the context of semi-supervised learning for HMMs. When auxiliary sensor data is available for only a small subset of tracked individuals, these known labels can be used to "supervise" and significantly improve the HMM's classification performance on the larger, unlabeled dataset [18].
Protocol for Semi-Supervised HMM Enhancement:
- Subset Identification: Identify the subset of tracking data (
S_supervised) for which high-confidence behavioral labels exist from auxiliary sensors. - Model Initialization: Use the labels in
S_supervisedto inform the initial parameters of the HMM's state-dependent distributions (e.g., initial estimates for the mean and variance of step length in the "foraging" state). - Constrained Training: Fit the HMM to the entire dataset (both supervised and unsupervised portions), but constrain the state sequence for the supervised portion
S_supervisedto match the known labels during the likelihood estimation process. - Performance Quantification: Evaluate the model's accuracy on the supervised subset before and after the semi-supervised fitting. Research on red-billed tropicbirds demonstrated that this method can increase overall accuracy from 0.77 to 0.85, even when the supervised subset represents only 9% of the total data [18]. This framework allows for continuous model refinement as more validated data becomes available.
Table 3: Key Research Tools for Behavioral Classification and Validation
| Tool / Reagent | Type | Primary Function in Behavioral Classification |
|---|---|---|
| GPS Loggers | Hardware | Provides core movement data (locations) for calculating step length and turning angle, the primary inputs for movement HMMs [9] [18]. |
| Tri-axial Accelerometer | Hardware | Delivers high-frequency data on body movement and posture, used for validating and defining behavioral states (e.g., flapping, running) [83] [29]. |
| Time-Depth Recorder (TDR) | Hardware | Validates diving and underwater foraging behavior in marine animals, providing ground truth for "foraging" states [18]. |
| Wet-Dry Sensor | Hardware | Infers periods of immersion (swimming/resting on water) versus terrestrial activity, aiding in state discrimination [18]. |
| DeepLabCut | Software | A markerless pose estimation software that uses deep learning to extract body keypoint coordinates from video, enabling precise motion capture for validation [3] [32]. |
| moveHMM / momentuHMM | Software | Specialized R packages providing user-friendly frameworks for fitting HMMs to animal tracking data, including functions for decoding state sequences and calculating model likelihoods [18]. |
| BEBE Benchmark | Dataset/Protocol | The Bio-logger Ethogram Benchmark provides a standardized framework and diverse, annotated datasets for comparing the performance of different machine learning methods, including HMMs, for behavior classification [29]. |
Conclusion
Hidden Markov Models provide a robust and interpretable framework for classifying animal behavior from tracking data, effectively bridging the gap between raw movement measurements and meaningful behavioral states. The foundational principles of HMMs allow researchers to model the sequential nature of animal behavior, while methodological advances enable applications across diverse species and experimental paradigms. Critical considerations around scale dependence and model selection must be addressed to ensure biological validity, with validation studies demonstrating HMMs' competitive performance against alternative machine learning approaches. For biomedical research and drug development, HMMs offer particularly valuable tools for quantifying behavioral phenotypes in disease models, assessing therapeutic efficacy, and detecting subtle behavioral changes in preclinical studies. Future directions should focus on developing standardized benchmarks, integrating multi-modal data streams, creating cross-species transfer learning frameworks, and advancing continuous-time modeling approaches to better capture the rich complexity of animal behavior.
References
- 1. Hidden Markov model [https://en.wikipedia.org/wiki/Hidden_Markov_model]
- 2. Hidden Markov Models [https://medium.com/@kootie73/hidden-markov-models-f9cb2b1ca853]
- 3. Hidden Markov Model‐Based Behavioral Classification ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12284846/]
- 4. Autoregressive Hidden Markov Models for High-Resolution ... [https://link.springer.com/article/10.1007/s13253-025-00705-6]
- 5. Hidden Markov Models and State Estimation [https://www.stat.cmu.edu/~cshalizi/dst/18/lectures/24/lecture-24.html]
- 6. Hidden Markov models: Theory, algorithms, and ... [https://www.eurekalert.org/news-releases/1103276]
- 7. Graphviz [https://graphviz.org/]
- 8. How to visualize a hidden Markov model in Python? [https://stackoverflow.com/questions/16852591/how-to-visualize-a-hidden-markov-model-in-python]
- 9. Scale dependence in hidden Markov models for animal ... [https://arxiv.org/html/2510.03958v1]
- 10. Hidden Markov models reveal behavioral state dynamics in ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0329367]
- 11. Hidden Markov Models Explained [https://www.digitalocean.com/community/tutorials/hidden-markov-models]
- 12. PyHHMM — PyHHMM 1.0.1 documentation [https://pyhhmm.readthedocs.io/]
- 13. Hidden Markov Model (HMM) Tutorial [http://practicalcryptography.com/miscellaneous/machine-learning/hidden-markov-model-hmm-tutorial/]
- 14. hmms [https://pypi.org/project/hmms/]
- 15. A hidden Markov movement model for rapidly identifying ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5383489/]
- 16. Method selection and temporal scale greatly influence ... [https://animalbiotelemetry.biomedcentral.com/articles/10.1186/s40317-025-00434-0]
- 17. Flexible hidden Markov models for behaviour-dependent ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-023-00392-3]
- 18. Animal behaviour on the move: the use of auxiliary information ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-023-00401-5]
- 19. Hidden Markov models identify major movement modes in ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-021-00243-z]
- 20. Flexible hidden Markov models for behaviour-dependent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10239607/]
- 21. Absolute direction in organelle movement - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11301659/]
- 22. Understanding speeding behavior from naturalistic driving ... [https://www.sciencedirect.com/science/article/abs/pii/S0001457519315593]
- 23. Hidden Markov Modeling Tutorial - GitHub Pages [https://mjones029.github.io/Tutorials/HMM_tutorial.html]
- 24. Markov Models and Cost Effectiveness Analysis - NCBI - NIH [https://www.ncbi.nlm.nih.gov/books/NBK543650/]
- 25. Rational Design of Profile Hidden Markov Models for Viral ... [https://www.ncbi.nlm.nih.gov/books/NBK569568/]
- 26. Hidden Markov Model (HMM) Explained [https://www.ultralytics.com/glossary/hidden-markov-model-hmm]
- 27. Application of Precision Technologies to Characterize Animal ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10854988/]
- 28. Accelerometer sampling requirements for animal behaviour ... [https://animalbiotelemetry.biomedcentral.com/articles/10.1186/s40317-023-00339-w]
- 29. A benchmark for computational analysis of animal behavior ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-024-00511-8]
- 30. Robust classification of animal tracking data [https://www.sciencedirect.com/science/article/abs/pii/S0168169907000026]
- 31. AlphaTracker: a multi-animal tracking and behavioral analysis ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10266280/]
- 32. Hidden Markov models reveal behavioral state dynamics in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12380309/]
- 33. Selfee, self-supervised features extraction of animal ... [https://elifesciences.org/articles/76218]
- 34. Hidden Markov Models - An Introduction [https://www.quantstart.com/articles/hidden-markov-models-an-introduction/]
- 35. 3.7. Hidden Markov Model (HMM) [https://bio-protocol.org/exchange/minidetail?id=2321725&type=30]
- 36. momentuHMM: Maximum Likelihood Analysis of Animal Movement Behavior Using Multivariate Hidden Markov Models [https://cran.r-project.org/web/packages/momentuHMM/index.html]
- 37. Visual Cliff Experiment (Gibson & Walk, 1960) [https://www.simplypsychology.org/visual-cliff-experiment.html]
- 38. Visual Cliff Test - Maze Engineers - ConductScience [https://maze.conductscience.com/portfolio/visual-cliff-test/]
- 39. Using deep learning to study emotional behavior in rodent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9722968/]
- 40. Hidden Markov Models: The Best Models for Forager ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0071246]
- 41. Linking movement and dive data to prey distribution models [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-023-00377-2]
- 42. Behavioral-dependent recursive movements and ... [https://www.nature.com/articles/s41598-023-43907-z]
- 43. Ecological drivers of movement for two sympatric marine ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-025-00542-9]
- 44. Search and foraging behaviors from movement data [https://pmc.ncbi.nlm.nih.gov/articles/PMC5756868/]
- 45. A new comprehensive approach to foraging strategies of a ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7882564/]
- 46. Uncovering ecological state dynamics with hidden Markov ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7702077/]
- 47. A brief introduction to mixed effects modelling and multi-model ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5970551/]
- 48. How to treat mixed behavior segments in supervised machine ... [https://movementecologyjournal.biomedcentral.com/articles/10.1186/s40462-024-00485-7]
- 49. Effects of Sampling Frequency on Human Activity ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12196717/]
- 50. On the relationship between sampling rate and Hidden ... [https://researchprofiles.tudublin.ie/en/publications/on-the-relationship-between-sampling-rate-and-hidden-markov-model-3/]
- 51. Robustness of brain state identification in synthetic phase ... [https://www.frontiersin.org/journals/systems-neuroscience/articles/10.3389/fnsys.2025.1548437/full]
- 52. Hidden Markov Models methods for selecting optimal ... [https://quant.stackexchange.com/questions/11045/hidden-markov-models-methods-for-selecting-optimal-number-of-states]
- 53. Using AIC and BIC for Model Selection - hmmlearn [https://hmmlearn.readthedocs.io/en/latest/auto_examples/plot_gaussian_model_selection.html]
- 54. The reporting and handling of missing data in longitudinal studies of older adults is suboptimal: a methodological survey of geriatric journals | BMC Medical Research Methodology | Full Text [https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-022-01605-w]
- 55. Missing data methods in longitudinal studies: a review - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC3016756/]
- 56. How to design a study flow chart [https://www.protocols.io/view/how-to-design-a-study-flow-chart-cfzhtp36]
- 57. Including irregular time intervals improves animal ... [https://www.psu.edu/news/research/story/including-irregular-time-intervals-improves-animal-movement-studies]
- 58. Text has enhanced contrast | ACT Rule | WAI [https://www.w3.org/WAI/standards-guidelines/act/rules/09o5cg/]
- 59. Elements must meet minimum color contrast ratio thresholds [https://dequeuniversity.com/rules/axe/4.8/color-contrast]
- 60. Decoding the Power of Hidden Markov Models [https://www.analyticsvidhya.com/blog/2023/11/hidden-markov-models/]
- 61. [2312.14583] Inference on the state process of periodically inhomogeneous hidden Markov models for animal behavior [https://arxiv.org/abs/2312.14583]
- 62. Validation framework for in vivo digital measures [https://www.frontiersin.org/journals/toxicology/articles/10.3389/ftox.2024.1484895/full]
- 63. vi-HMM: a novel HMM-based method for sequence variant ... [https://humgenomics.biomedcentral.com/articles/10.1186/s40246-019-0194-6]
- 64. Artificial Intelligence: Hidden Markov Model Classifiers and ... [https://www.skyradar.com/blog/artificial-intelligence-hidden-markov-model-classifiers-and-radar-objects-classification-by-machine-learning-2-2]
- 65. Hidden Markov Model and Support Vector Machine based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3901317/]
- 66. HMM, MEMM, and CRF: A Comparative Analysis of ... [https://www.alibabacloud.com/blog/hmm%2C-memm%2C-and-crf%3A-a-comparative-analysis-of-statistical-modeling-methods_592049]
- 67. A Comparative Study between Hidden Markov Model and ... [https://www.sciencedirect.com/science/article/pii/S1877705816307263]
- 68. Validating hidden Markov models for seabird behavioural ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10911961/]
- 69. Machine learning for inferring animal behavior from ... [https://www.sciencedirect.com/science/article/pii/S1574954118302036]
- 70. Proper account of auto-correlations improves decoding ... [https://peercommunityjournal.org/item/10_24072_pcjournal_535/]
- 71. A benchmark for computational analysis of animal , using... behavior [https://arxiv.org/html/2305.10740v3]
- 72. earthspecies/BEBE: The Biologger Ethogram Benchmark [https://github.com/earthspecies/BEBE]
- 73. Animal Behavior Analysis Methods Using Deep Learning [https://arxiv.org/abs/2405.14002]
- 74. Toward human-level concept learning: Pattern benchmarking ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10435961/]
- 75. Neural Network Vs Markov Models [https://www.meegle.com/en_us/topics/neural-networks/neural-network-vs-markov-models]
- 76. Efficient shallow learning as an alternative to deep learning [https://www.nature.com/articles/s41598-023-32559-8]
- 77. Hidden Markov Model in Machine Learning [https://thepermatech.com/hidden-markov-model-in-machine-learning/]
- 78. AlphaTracker: a multi-animal tracking and behavioral ... [https://www.frontiersin.org/journals/behavioral-neuroscience/articles/10.3389/fnbeh.2023.1111908/full]
- 79. ezTrack - A step by step guide to behavior tracking - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC8500532/]
- 80. The quest to develop automated systems for monitoring ... [https://www.sciencedirect.com/science/article/pii/S0168159123001727]
- 81. A Closer Look at Classification Evaluation Metrics and ... [https://arxiv.org/html/2404.16958v1]
- 82. Evaluation metrics and statistical tests for machine learning [https://www.nature.com/articles/s41598-024-56706-x]
- 83. An artificial neural network for automated behavioral state ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8435206/]
- 84. LabGym: Quantification of user-defined animal behaviors ... [https://www.sciencedirect.com/science/article/pii/S2667237523000267]